Assessing the project overview and defining activities and deliverables
Learning objectives
|
This module will review the overall objectives that your project will address. After completing this module, you should be able to perform the following:
|
Presentation
| In this presentation, we will introduce some of the keys aspects we expect to see in a project full proposal submitted under a GBIF-managed call. |
Presentation transcript
Click to expand

Slide 1 - Assessing project overview and defining activities and deliverables
In this presentation, we will introduce some of the key aspects we expect to see in a project full proposal submitted under a GBIF-managed call.

Slide 2 - General Tips
To begin, we’d like to list a few tips that can be applied throughout your project proposal:
You should continue to build upon the content of your concept note. If you have been selected to submit a full proposal, this means that the reviewers found merit in your concept note. Thus, it is important to build on it by considering the recommendations and feedback communicated by the evaluation panel. Update and expand any section as relevant.
Addressing the feedback you received on your concept note is a criterion of evaluation. The reviewers will expect that any identified issues or recommendations will be addressed in your full proposal. If you believe that is not feasible to address a specific feedback, then you should give a rationale explaining why.
In general, be brief and clear. Answer each section as clearly as possible and make sure you focus on the main message you want to convey. Only add background or additional information if really needed and preferably through links to background documents and/or external resources.
Slide 3 - Project overview
The first part of the project proposal contains the project overview and this information provides a high-level overview of your project.
This includes: the overall objective, expected outcomes/impacts, the project description, and the expected use of the data to be mobilized by the project.
All of this information was ported from the concept note to your full proposal. It is not necessary to change the information in these sections unless warranted through your response to feedback from reviewers or to better state the relevance of your project for regional priorities or in support of the Global Biodiversity Framework.
Slide 4 - Activities and deliverables
Since the project overview is at a high-level, you then need to get into the specifics in the next section of the proposal with your project activities and deliverables.
Each activity should directly contribute to the objective(s) set forth in your project.
Each activity will have a companion deliverable or impact. And each activity will contribute to an Activity area. Additionally, as all projects funded through the BID programme have a mobilization component, you will also detail any datasets you expect to deliver as part of the project in this section.
To write effective activities and deliverables, you may want to take inspiration with the SMART framework. SMART is the acronym for Specific, Measurable, Achievable, Relevant, and Time-bound. This framework helps you to define what you want to achieve, how you’ll measure progress, ensure it’s realistic, aligns with overall objective, and when it will be complete. And as a part of being specific, this is also a good opportunity to define who (perhaps a specific role or team) will be responsible for completing the activities and deliverables. Use what makes sense for your project in your activity and deliverable descriptions.

Slide 5 - Activity areas
Depending on your grant type, your activities must relate to a specific Activity area.
Activities in the mobilizing biodiversity information area, should focus on digitizing and sharing existing sources of biodiversity data through GBIF.
Activities in the supporting the integration of biodiversity information into research and policymaking processes area should demonstrate the practical use of open biodiversity data.
Activities in the building and expanding data-sharing networks area should should focus on creating or strengthening sustainable collaborations for biodiversity data sharing.

Slide 6 - Glossary terms
GBIF has some specific terminology when it comes to mobilization projects which might be helpful during your proposal writing process.
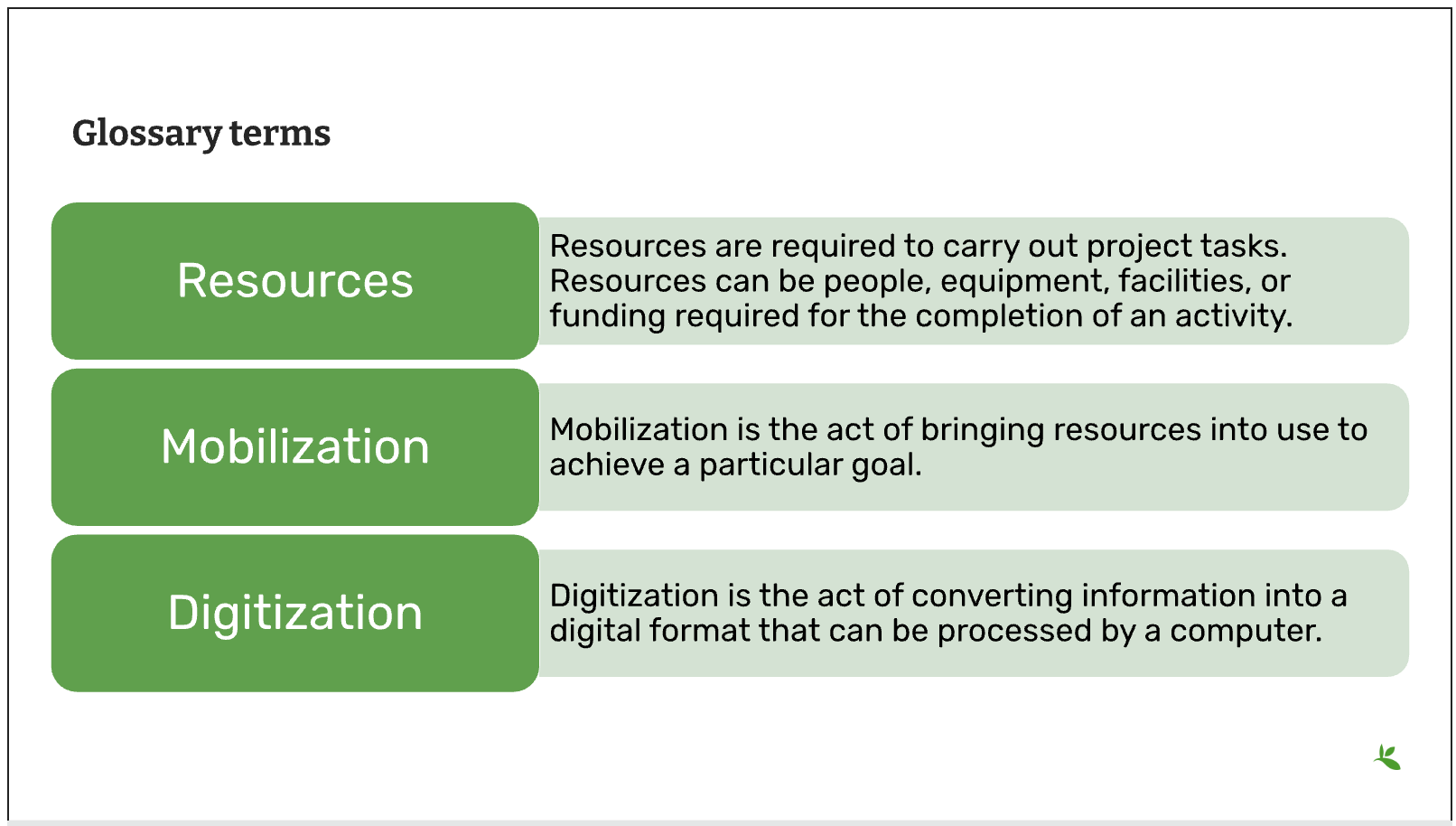
Slide 7 - Glossary terms
-
In project management terminology, Resources are required to carry out project tasks. Resources can be people, equipment, facilities, or funding required for the completion of an activity.
-
Mobilization is the act of bringing resources into use to achieve a particular goal.
-
Digitization is the act of converting information into a digital format that can be processed by a computer.

Slide 8 - Glossary terms - dataset types
There are several classes of datasets supported by GBIF that start simple and become progressively richer, more structured and more complex. We encourage all BID applicants and participants to aim in making their datasets as rich as possible to support wider use of the data.

Slide 9 - Glossary terms - dataset metadata only
A biodiversity data holding otherwise known as a metadata-only dataset is the simplest type of dataset that can be shared on GBIF. They allow participants to highlight and describe data that may not be available online yet. Metadata-only datasets can be particularly useful in regions where there is a need to identify possible sources of biodiversity data. They can describe for example, undigitized or untranscribed biodiversity-related documents.

Slide 10 - Glossary terms - dataset - Checklist
Species or taxon lists otherwise known as checklists are a richer type of dataset available on GBIF. They can help capture and share information at the taxon level, such as taxonomy, or properties (e.g. invasive, vernacular names, threatened, etc.) of a given list of taxa. Checklists must contain individual taxon records and their relevant associated fields.

Slide 11 - Glossary terms - dataset - Occurrence
Occurrence datasets contain records of observations or collections of a given set of organisms at a given time and place. In addition to the GBIF dataset requirements, occurrence datasets must also contain individual occurrence records with the following information (“What? Where? When?”):
The number of records in occurence dataset could be range from small to quite large. If an institution decides to share all their records, they might choose to publish multiple datasets over thematic groups.
One last note related to record counts with respect to occurrences with associated images.
an occurrence record equals one organism observed or collected at a given location and at a given time.
1 observation + 5 images of that same observation from different angles = 1 occurrence record + 5 associated images (not 5 occurrences) 1 herbarium specimen + 3 different scans of the herbarium sheet = 1 occurrence record + 3 associated images
Associated images can be shared along side occurrences in an occurrence dataset.

Slide 12 - Glossary terms - dataset – Sampling event
Sampling-event, survey and monitoring datasets are the richest type of datasets available on GBIF.
Sampling-event data describes species occurrences in time and space together with details of sampling effort. Such data is available from thousands of environmental, ecological, and natural resource investigations. These can be one-off studies or monitoring programs. Such data are usually quantitative, calibrated, and follow certain protocols so that changes and trends of populations can be detected.
All sampling event datasets contain occurrences. They also contain records of events and information about the sampling context (“how?”). These can be captured in event fields (like sampling protocol, sample size value and unit, sampling efforts) or in the Humbolt extension for ecological repositories.
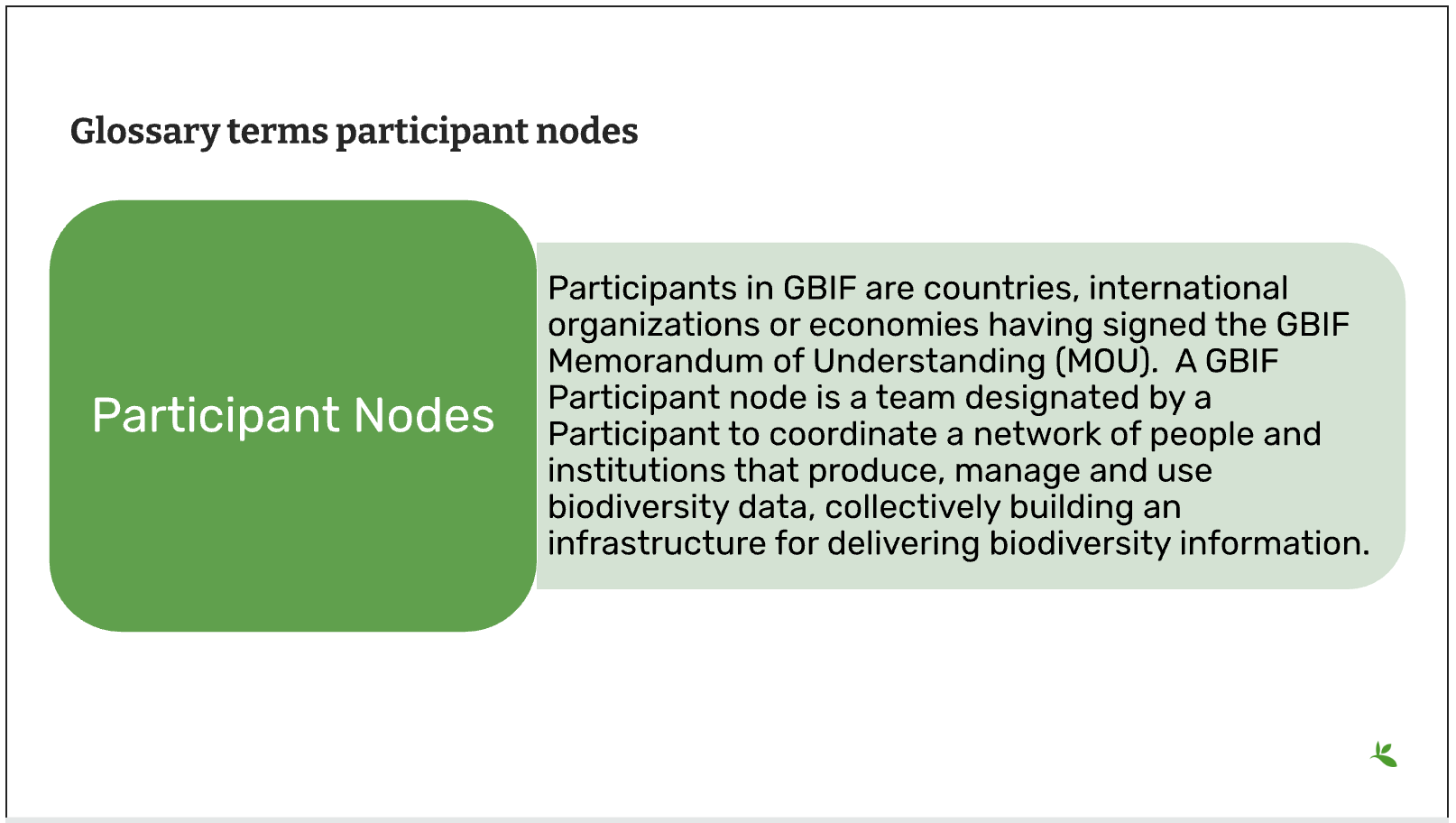
Slide 13 - Glossary terms - Participant nodes
Participants in GBIF are countries, international organizations or economies having signed the GBIF Memorandum of Understanding (MOU). A GBIF Participant node is a team designated by a Participant to coordinate a network of people and institutions that produce, manage and use biodiversity data, collectively building an infrastructure for delivering biodiversity information.
BID projects in countries with Participant Nodes are encouraged to establish communication and collaboration with their Node.

Slide 14 - Glossary terms – data holders and endorsement as a publisher
A data holders are Organizations that hold biodiversity data and are interested in sharing that data and a willing to become an endorsed publisher with GBIF.
At present, the GBIF network only publishes datasets directly from organizations. It is common to secure institutional agreements (either informally or formally) stating their desire to share their data with your project and GBIF. Once a data holder agreement is conferred with the project, the next step is request endorsement as a publisher. This can be done by the data holding organization or you can facilitate it on their behalf.
We encourage you to request endorsement for the organization as soon as possible to avoid delays in publishing data. If the country is a GBIF participant node, the endorsement request will be reviewed for approval by the Node Manager in that country. If the country is not a Participant, then the Nodes Steering Group will review the endorsement for approval.

Slide 15 - Indigenous data considerations
We would like to raise some points regarding Indigenous data in the context of BID project proposals, and we would like to encourage anyone working with Indigenous data to refer to some core concepts:
Indigenous data sovereignty is the right of Indigenous Peoples to exercise control over Indigenous data across all phases of the data lifecycle, and recognizes Indigenous Peoples as data creators, data stewards and knowledge experts.
Indigenous data governance is the policies and practices that support Indigenous Peoples in applying Indigenous data sovereignty to govern, collect, store, analyze, use and manage the application of Indigenous data.
The CARE data principles are an important reference for considering how these concepts can relate to open data.
Designed to complement the FAIR Principles, the CARE Principles affirm the rights of Indigenous and local peoples, nations and communities to act as self-determining custodians and users of open data. The four principles—Collective benefit, Authority to control, Responsibility and Ethics—provide a framework for aligning the actions of GBIF network members toward more equitable biodiversity data and data practices throughout the data lifecycle.

Slide 16 - Glossary terms - Data users
Data users are individuals who query and download data from GBIF for use in research and policymaking. It may be useful to query data users in your community to understand what kinds of data they will want to use or what kinds of products they want to produce.

Slide 17 - Project considerations
When you finish your proposal you should be able to answer all of these questions.
-
What will this project accomplish, both in terms of records published and increased capacity?
-
What are the project’s expected deliverables?
-
Why is the data mobilized by the project needed?
-
Who will it benefit and how?
-
Are there considerations regarding Indigenous data sovereignty and governance that relate to the data mobilization effort in the project?
-
What are the time and staffing requirements for each activity? Does the plan align with the overall project duration?
-
How will data mobilization activities be sustained into the future?
Slide 18 - Thank you
Activity
| Check your understanding of the dataset types with published records. Rationale is provided below the quiz. If you need assistance choosing your own dataset type, review the blog post on Choosing a dataset type. |
-
What dataset type(s) would you choose for an ichthyology collection?
-
occurrence
-
checklist
-
sampling event
 Eutrigla gurnardus (Linnaeus, 1758) | Muséum d’histoire naturelle de Nice
Eutrigla gurnardus (Linnaeus, 1758) | Muséum d’histoire naturelle de Nice-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for a list of invasive species?
-
occurrence
-
checklist
-
sampling event
 Water hyacinth (Eichhornia crassipes) observed in Bourail, New Caledonia, where it is an introduced and invasive species by GRIIS. Photo by gérard (2016) licensed under CC BY-SA 2.0
Water hyacinth (Eichhornia crassipes) observed in Bourail, New Caledonia, where it is an introduced and invasive species by GRIIS. Photo by gérard (2016) licensed under CC BY-SA 2.0-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for the flora and fauna of an environmental impact study?
-
occurrence
-
checklist
-
sampling event
Environmental impact assessment studies are done by experts in order to assess the biodiversity and biotopes of a given area, before, during and after it is affected by human activities (road works, wind turbines, mining, building construction, etc.).
 Entomologist chasing butterflies by Matthieu Gauvain (CC-BY-SA)
Entomologist chasing butterflies by Matthieu Gauvain (CC-BY-SA)-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for bird tracking data?
-
occurrence
-
checklist
-
sampling event
Bird-tracking data are recorded using specific devices, such as GPS trackers mounted on live birds, thus allowing scientists to track their migratory routes or breeding sites.
 Griffin vulture observed at Gamla Nature Reserve by מינוזיג - MinoZig (CC0)
Griffin vulture observed at Gamla Nature Reserve by מינוזיג - MinoZig (CC0)-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for insect trap data?
-
occurrence
-
checklist
-
sampling event
 Insect trap by miheco (CC-BY-SA)
Insect trap by miheco (CC-BY-SA)-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for national park management data?
-
occurrence
-
checklist
-
sampling event
Data acquired in the context of protected areas management (such as national parks but also smaller nature reserves) can be diverse and have different origins: botanical surveys, tagged animals tracking, observations from rangers and guards, and even ‘citizen science’ data or data inferred from pictures shared on social medias.
 Sri Lankan elephants observed by pen_ash.
Sri Lankan elephants observed by pen_ash.-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for a citizen science bioblitz?
-
occurrence
-
checklist
-
sampling event
Citizen science data are often collected through thematic fieldwork days known as a “bioblitz.” Volunteers typically gather in a given area and spend the day trying to observe and identify as many species as they can in this area.
Data from each participant are captured and merged into the citizen science programme’s data capture or data management tool.
 Looking for birds with park staff by US National Park Service (authorized reuse on google image search)
Looking for birds with park staff by US National Park Service (authorized reuse on google image search)-
occurrence
-
checklist
-
sampling event
-
-
What dataset type(s) would you choose for a regional species list?
-
occurrence
-
checklist
-
sampling event
 Black rhino observed at the Magdeburg Zoo in Germany by Mani300
Black rhino observed at the Magdeburg Zoo in Germany by Mani300-
occurrence
-
checklist
-
sampling event
-
{kind=link}
{kind=link}
Dataset types quiz rationale
Click to expand
If you need assistance choosing your own dataset type, review the blog post on Choosing a dataset type.
What dataset type(s) would you choose for an ichthyology collection?
-
occurrence
Most of the time, specimens from collection databases are shared as occurrence data. Each occurrence (specimen or group of specimens) has its own unique identifier (sometimes derived from its catalogue number in the source collection) and the Darwin Core fields used to share them within GBIF describe each specimen: scientific name, the date it was collected on the field, who collected and/or identified it, where, etc. Each collection can have more than one specimen from a same species, as long as each specimen is identified by a unique ID. -
checklist
It is also possible to create and share a taxonomical checklist derived from a collection database; in this case, it is recommended to share the checklist as a taxonomical dataset, with the occurrence (specimen) list associated with it by using the Occurrence core as an extension to the Taxon Core on the GBIF IPT.
What dataset type(s) would you choose for a list of invasive species?
-
occurrence
Some data publishers will share occurrence datasets coming from studies or programs tracking specimens from some specific invasive species; when the data focuses on individuals instead of the invasive species, in general, they can be shared as occurrence data. -
checklist
Invasive species can be tracked and monitored at different scales (regional, national, thematic…); as this type of dataset focuses more on the species and their distribution across a given geographical scope, they are mainly shared as taxonomical datasets within GBIF (see GRIIS search results).
What dataset type(s) would you choose for the flora and fauna of an environmental impact study?
-
occurrence
Data are recorded by naturalists on the field and can be shared as simple occurrence datasets. -
sampling event
They can also be shared as event datasets if standardized protocols (such as vegetation plots, transects, traps…) are used to collect the data.
What dataset type(s) would you choose for bird tracking data?
-
occurrence
These data are shared as occurrence datasets: ideally, each bird is identified with its organismID, and each occurrence (GPS ping) has its own occurrenceID, which is useful to track the different GPS locations of the same bird over the scope of the tracking programme or project. (See example)
What dataset type(s) would you choose for insect trap data?
-
occurrence
Although such data can be shared as simple occurrence datasets, it is best if they’re shared as event datasets, where the location, identifier and contents of each trap can be better detailed. -
sampling event
Insect traps (as well as other traps such as pitfall traps, malaise traps…) are typically used in monitoring programmes to check the presence (or absence) of some species and/or assess their specific abundance. Using the “eventID” field to identify each trap allows the users to get all of the specimens collected within each trap. The same logic applies to other field protocols such as transects, plots, remote cameras, etc.: by using the Event Core instead of the Occurrence core, you’ll be able to share much more information about the context of the data collection, and allow users to better understand (and even replicate) your work.
What dataset type(s) would you choose for national park management data?
-
occurrence
record individuals of species -
checklist
It is important to know how many species are present in the park/reserve perimeter and their conservation status. -
sampling event
check and track the populations
What dataset type(s) would you choose for a citizen science bioblitz?
-
occurrence
Bioblitz datasets are mainly shared as occurrence datasets. -
sampling event
Depending on the citizen science programme, specific sampling protocols might be used by the volunteers, in which case, the data can be shared as an event dataset.
What dataset type(s) would you choose for a regional species list?
-
checklist
Geographical or thematic species lists are often used to share information about the species present in a given area; most of the time, these lists also mention the distribution of each species as well as their conservation status in this area. Regional species lists can give a useful insight into a region’s biodiversity and habitats, and need to be shared as taxonomical datasets, with or without associated occurrences.