Captura de datos
|
En este módulo, aprenderá sobre el concepto de estándares, en particular, el Estándar Darwin Core y sus componentes. También aprenderá los tipos de datos primarios sobre biodiversidad y la mejor manera de compartir esa información dentro de GBIF. Por último, revisará los principios de calidad de los datos en el contexto de la captura de datos y aprenderá sobre la calidad y la coherencia de los datos (especialmente en temas como la georreferenciación, las fechas, los nombres y la verificación cruzada de taxones). |
Estándares y Darwin Core
|
En este video (23:25), aprenderá cómo interactúa con los estándares a diario. A continuación, se le presentarán los Estándares de Información sobre Biodiversidad (https://www.tdwg.org/standards/dwc/), incluyendo el Estándar Darwin Core (https://www.tdwg.org/standards/dwc/), que utilizará a lo largo de este curso. Los subtítulos aún no están disponibles para este video. Si no puede ver el vídeo incrustado, puede descargarlo localmente. (MP4 - 71,5 MB)download (MP4 - 71.5 MB) Si prefieres leer, encontrarás la transcripción debajo del vídeo incrustado. |
Transcripción de la presentación
Haga clic para ampliar

Diapositiva 1 - Estándares y el Darwin Core
En esta presentación, les presentaremos los estándares de datos relacionados con la biodiversidad. En particular, nos centraremos en el estándar Darwin Core.

Diapositiva 2 - Estándares: Pongámonos de acuerdo
El ingeniero e industrial W. Edwards Deming dijo:
“La estandarización no significa que todos vistamos ropa del mismo color y tipo, comamos sándwiches estándar o vivamos en habitaciones estándar con muebles estándar. Las casas, con una infinita variedad de diseños, se construyen con unos pocos tipos de ladrillos, con madera de tamaños estándar y con tuberías y accesorios de agua y calefacción de dimensiones estándar.”
Lo que intentaba decir es que el uso de la estandarización no nos impide ser creativos. También nos estaba mostrando que ya vivimos rodeados de estándares.
A medida que avancemos, definiremos el término «estándar» y analizaremos cómo interactuamos con los estándares a diario. Posteriormente, les presentaremos los estándares de información sobre biodiversidad, incluido el Estándar Darwin Core, que seguirán utilizando a lo largo de este curso.

Diapositiva 3 - ¿Qué es un estándar?
Entonces, ¿Qué es un Estándar?
En su forma más sencilla es:
"Una forma acordada de hacer algo."
Los estándares son combinaciones de normas, convenciones, especificaciones, requisitos, restricciones y reglas.

Diapositiva 4 - Estándares cotidianos
El propósito principal de los estándares es crear un marco de "comprensión mutua". Deben proporcionar claridad y ayudar a la comunicación.
Algunos ejemplos de cosas cotidianas con las que nos encontramos y que utilizan estándares para facilitar la comunicación de información son:
-
Unidades de Medida
-
Sistemas Numéricos
-
Alfabetos
-
Idiomas
-
Emojis
-
Dirección Postal
-
Código Morse
-
Código de Barras
Imagen de medición de Arek Socha de Pixabay https://pixabay.com/photos/measurement-millimeter-centimeter-1476913/ Imagen de números de Clker-Free-Vector-Images de Pixabay https://pixabay.com/vectors/numerals-roman-number-blocks-35937/ Imagen del alfabeto de https://en.wikipedia.org/wiki/Alphabet#/media/File:Historical_Writing_Systems_Template_Image.jpg Imagen de idiomas de Christopher Kuszajewski de Pixabay https://pixabay.com/photos/source-code-code-programming-c-583537/ Imagen del Código Morse de https://en.wikipedia.org/wiki/Morse_code#/media/File:International_Morse_Code.svg Imagen de correo de OpenClipart-Vectors de Pixabay Imagen de emojis de https://en.wikipedia.org/wiki/Emoticon#/media/File:Emoticon_Smile_Face.svg Imagen de código de barras de IBOL https://ibol.org/site/wp-content/uploads/2018/12/bookmark-vectors.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Diapositiva 5 - Estándar cotidiano - Un ejemplo
Tomemos un ejemplo muy específico y desglosémoslo. En orden de comunicar, de manera precisa y repetida una posición en la tierra – una latitud y una longitud – es en realidad una combinación de al menos 8 estándares.
medición - formato de las coordenadas geográficas - sistema numérico de grados, minutos y segundos - números sexagesimales - lengua indoárabe - alfabeto inglés - símbolos latinos - fuente tipográfica - Roboto

Diapositiva 6 - Reglas y restricciones
Los estándares ofrecen maneras de limitar el abanico de posibilidades. En las presentaciones anteriores de Fundamentos, aprendieron sobre tipos de datos, esquemas, formatos y codificaciones de caracteres. Cada uno de estos elementos puede utilizarse para limitar el abanico de posibilidades dentro de los términos de un estándar.
Los tipos de datos pueden restringir los valores de un campo. Entonces, texto alfanumérico en un campo de texto, decimales en un flotante. Sí / No en un booleano.
Un esquema de codificación puede restringir el rango de valores en un campo. Por ejemplo, la lista de posibles valores de latitud tiene un rango: entre -90 y 90.
Un formato puede restringir la representación de datos en un campo. Por ejemplo, si un dato aparece como día del mes del año, o año del mes del día, o año del mes.
A continuación, la codificación de caracteres proporciona las reglas para interpretar los bytes de datos. Para nuestros propósitos, utilizaremos UTF-8.
Foto: Eurema blanda (Boisduval, 1836) observada en Nepal por Bird Explorers (http://creativecommons.org/licenses/by-nc/4.0/)

Diapositiva 7 - Estándares para la transferencia de datos
Durante este curso, aprenderá a compartir sus datos. Como tal, se encontrará con normas para la transferencia de datos.
Un esquema de aplicación, permite la combinación de estándares de datos para un propósito específico. Por ejemplo, utilizando términos de Darwin Core dentro de los Archivos de Darwin Core. Profundizaremos más en ambos en solo unos momentos.
Nuevamente, utilizará el formato, pero esta vez el formato restringe las estructuras del conjunto de datos. Un conjunto de datos puede hacer uso de csv, xml, json y rdf.
Y por último, dispondrá de un protocolo de transferencia, que proporciona información sobre cómo y dónde enviar la información. Estos pueden incluir http (protocolo de transferencia de hipertexto), ftp (protocolo de transferencia de archivos) y smtp (protocolo simple de transferencia de correo o, si lo desea, enviar correo a las personas).
Imagen de Gerd Altmann de Pixabay https://pixabay.com/illustrations/web-network-computer-digital-5371553/

Diapositiva 8 - Estándares de Información sobre Biodiversidad
En el campo de la informática de la biodiversidad, ya hay muchos estándares disponibles que pueden ayudarlo a trabajar con sus datos. El USGS tiene una definición muy específica de estos:
“Los estándares de datos son las reglas mediante las cuales se describen y registran los datos. Para compartir, intercambiar y comprender datos, debemos estandarizar tanto el formato como el significado.
El resultado de utilizar estos estándares, cuando corresponda, es que aumentará la integridad, exactitud y coherencia de los datos al aclarar el significado ambiguo y minimizar los datos redundantes.
Entre los que probablemente encontrará o utilizará de forma habitual se incluyen:
Ecological Metadata Language Standard (EML) Humboldt Ecological Inventory (Humboldt extension) Global Genome Biodiversity Network(GGBN) Ocean Data Standards and Best Practices Project (ODSBP) (Red Mundial de Biodiversidad Genómica)
Y por último, pero no menos importante, dedicaremos el resto de esta discusión a Darwin Core. El estándar Darwin Core le permitirá compartir sus conjuntos de datos de registros biológicos, listas de especies y eventos de muestreo.
Referencias: EML - https://knb.ecoinformatics.org/#external//emlparser/docs/index.html Audubon - https://terms.tdwg.org/wiki/Audubon_Core GGBN - http://wiki.ggbn.org/ggbn/GGBN_Data_Standard ODSBP - https://www.iode.org/index.php?option=com_content&view=article&id=369&Itemid=100083 DwC - http://rs.tdwg.org/dwc/
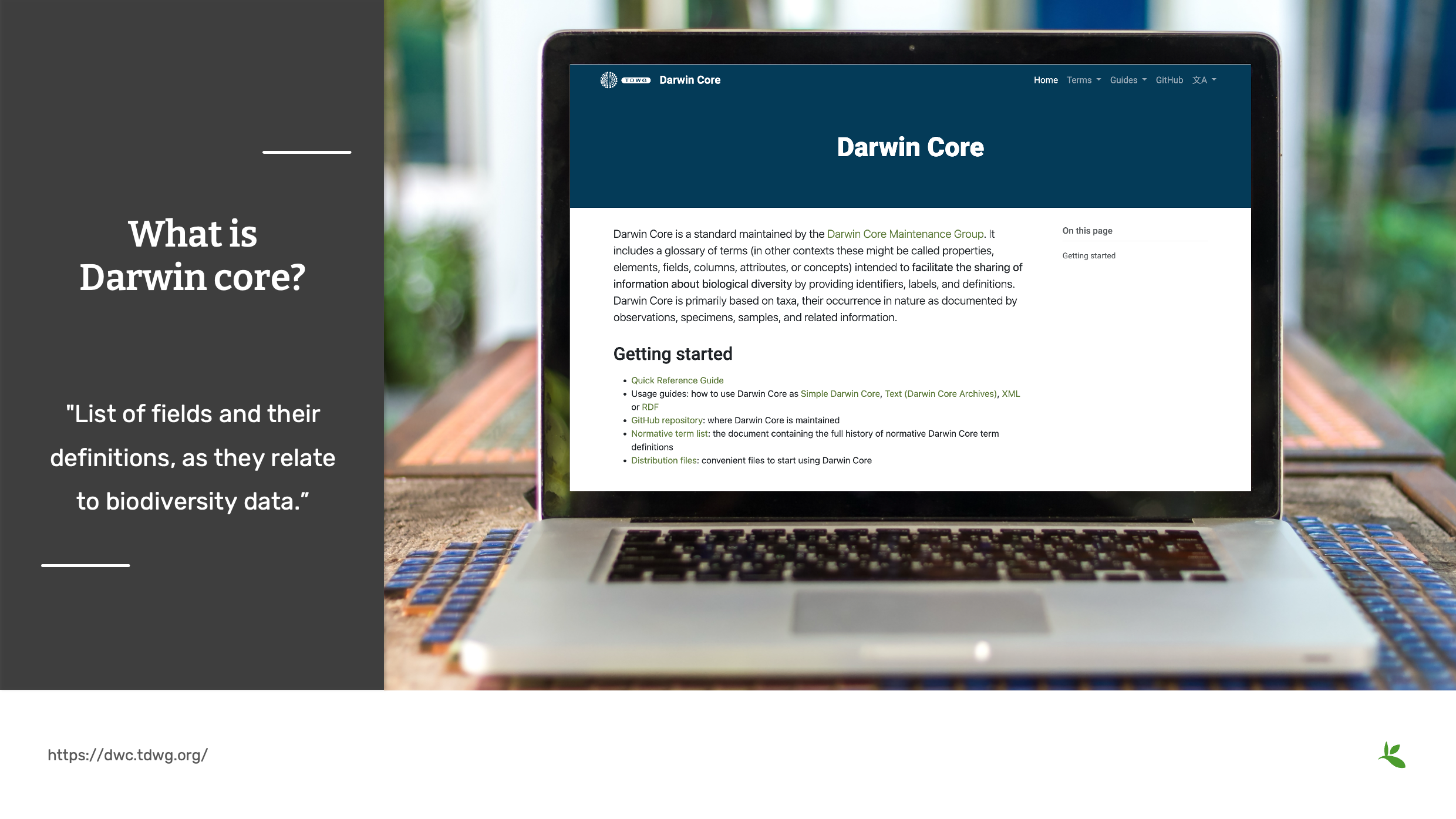
Diapositiva 9 - Qué es Darwin Core
Darwin Core es un estándar de biodiversidad desarrollado por la comunidad de Biodiversity Informatics. Originalmente fue desarrollado bajo el Grupo de Trabajo de Bases de Datos Taxonómicos (Taxonomic Databases Working Group) o T D W G, pronunciado TDWG. En los últimos años, el grupo ha cambiado de nombre, Estándares de Información sobre Biodiversidad (Biodiversity Information Standards). Pero el acrónimo persiste ya que a la comunidad le gusta mucho el nombre TDWG.
“El estándar incluye un glosario de términos (en otros contextos, estos pueden denominarse propiedades, elementos, campos, columnas, atributos o conceptos) destinados a facilitar el intercambio de información sobre la diversidad biológica proporcionando identificadores, etiquetas y definiciones. Darwin Core se basa principalmente en taxones, su presencia en la naturaleza según lo documentado por observaciones, especímenes, muestras e información relacionada."
En resumen, Darwin Core es un
"Lista de campos y sus definiciones, en relación con los datos sobre biodiversidad."

Diapositiva 10 - Simple Darwin Core
A medida que profundicemos en Darwin Core o como se abrevia, DwC, aprenderá que es más que SOLO una lista de campos. Usaremos Simple Darwin Core, que es un subconjunto predefinido de los términos que tienen un uso común en una amplia variedad de aplicaciones de biodiversidad.
Este subconjunto contiene más de 150 campos, que se colocan en un conjunto de clases de campo compuesto por:
Registro y Conjunto de Datos Registro Biológico Organismo Material Entidad Material Muestra Evento Localización Contexto Geológico Identificación Taxón
Además, hay dos clases auxiliares llamadas:
RecursoRelación MedidaOHecho
Según la Guía del Usuario de Simple Darwin Core, "Simple Darwin Core es simple en el sentido de que no presupone (ni permite) ninguna estructura más allá del concepto de filas y columnas, que podrían considerarse como atributos y sus valores, o campos y registros."
Foto: Macaca mulatta (Zimmermann, 1780) observada en Nepal por Vladimir Tkalčić (http://creativecommons.org/licenses/by-nc/4.0/)
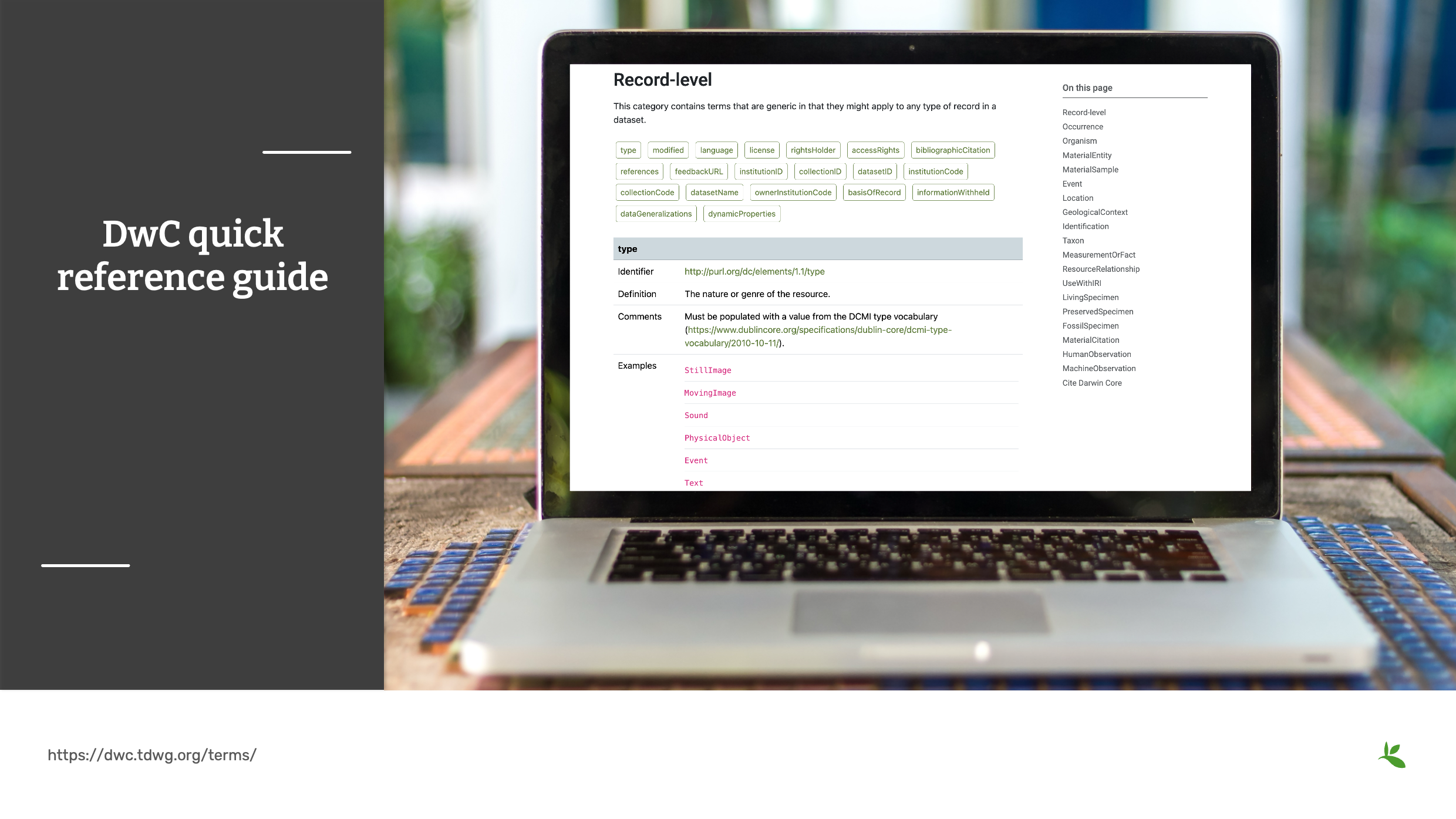
Diapositiva 11 - Guía de Referencia Rápida de Darwin Core
La Guía de Referencia Rápida de DwC (DwC Quick Reference Guide) pronto se convertirá en su recurso de referencia. Esta página proporciona una lista de todos los términos recomendados actualmente del estándar Darwin Core. Categorías como Registro Biológico (Ocurrence) o Evento (Event) corresponden a clases de Darwin Core que agrupan otros términos.

Diapositiva 12 - Términos DwC country y countryCode
Ahora veremos algunos ejemplos de términos de Darwin Core. La guía de referencia rápida muestra consecuentemente cada término con el nombre del identificador, la definición, los comentarios y los ejemplos.Los primeros términos que revisaremos son País (country) y Código de País (countryCode) dentro de la categoría Ubicación (Location).
Generalmente, los custodios de datos tienen un campo para el país dentro de sus datos de origen. Pero, a menudo, estos datos pueden ser bastante confusos con errores ortográficos, abreviaturas y nombres históricos. Sin embargo, es uno de los datos más fáciles de estandarizar. Como se indica en los comentarios, la mejor práctica recomendada es utilizar un vocabulario controlado como el Tesauro de Nombres Geográficos de Getty. Un vocabulario controlado impone restricciones a los valores que deben usarse para ese término.
CountryCode es un término que no suele estar presente en los datos del titular. Pero, de nuevo, es otro campo que puede suministrarse fácilmente con datos debido a la recomendación en los comentarios de utilizar un código de país ISO 3166-1-alfa-2.
GBIF recomienda fuertemente compartir el Código de País (CountryCode) dentro de los conjuntos de datos de registros biológicos.También se recomienda a compartir el País (Country).
Aprenderá más sobre los requisitos y recomendaciones de GBIF en sesiones posteriores.
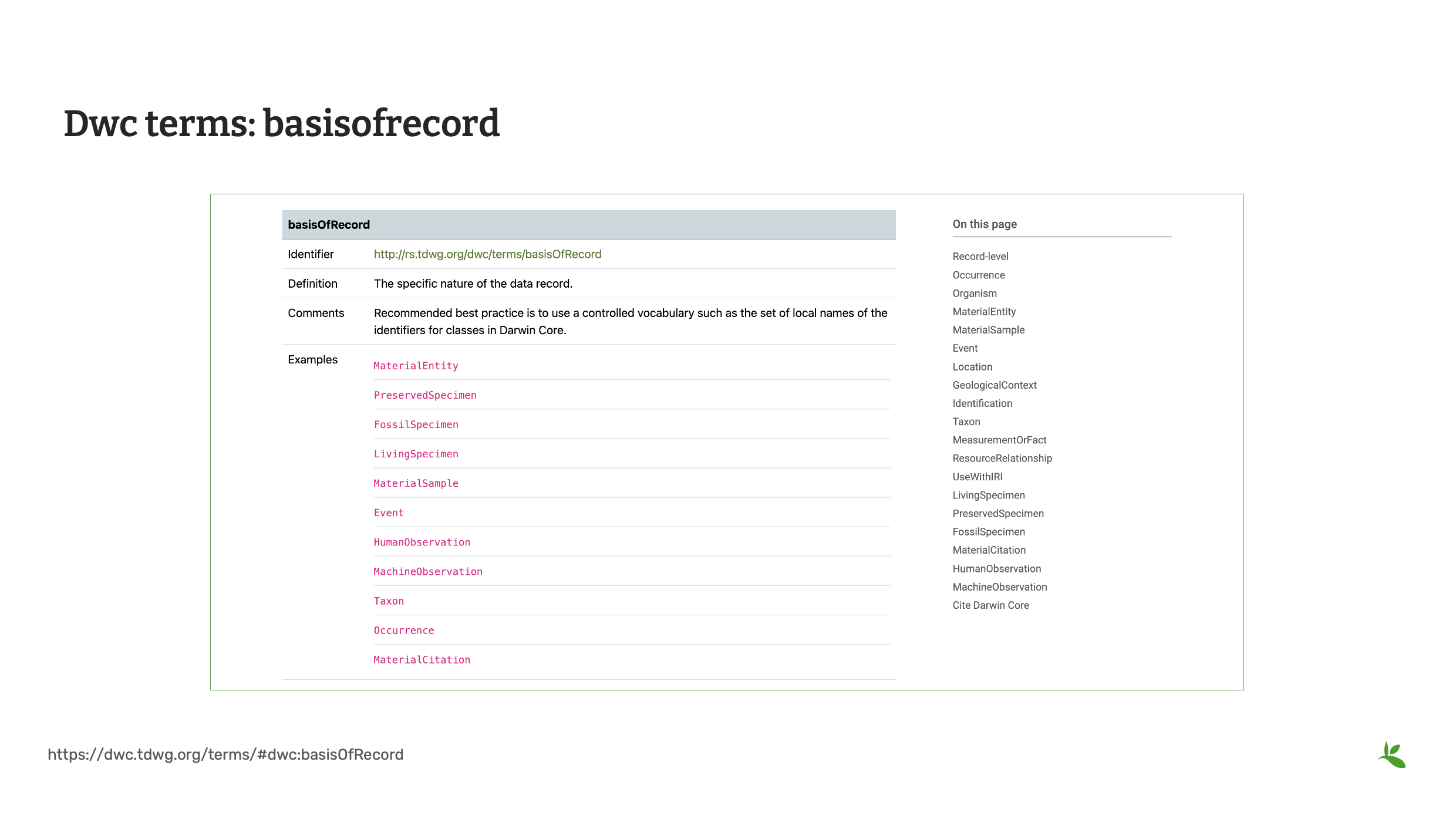
Diapositiva 13 - Términos DwC basisOfRecord
El siguiente término es Base del Registro (basisOfRecord). basisOfRecord define la naturaleza de cada registro en un conjunto de datos. basisOfRecord sigue un vocabulario controlado. Puede elegir entre Espécimen Preservado (PreservedSpecimen), Espécimen Fósil (FossilSpecimen), Espécimen Vivo (LivingSpecimen), Muestra de Material (MaterialSample), Evento (Event), Observación Humana (HumanObservation), Observación de Máquina (MachineObservation), Taxon o Registro (Occurrence). GBIF requiere que basisOfRecord sea publicado con los conjuntos de datos de registros biológicos.
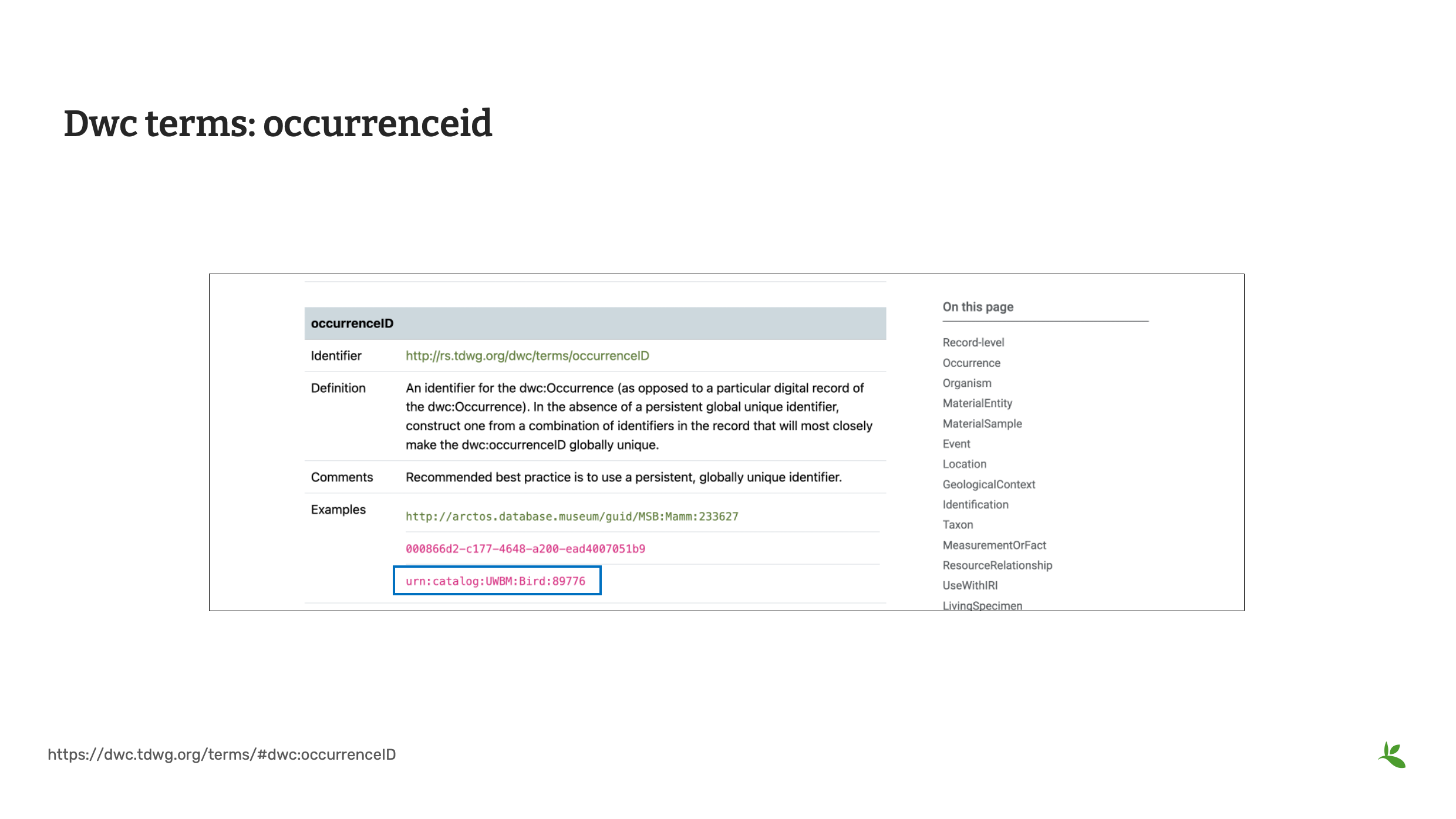
Diapositiva 14 - Términos DwC occurrenceID
El último término que revisaremos es occurrenceID. Al publicar registros biológicos, GBIF requiere un occurrenceID. Un occurrenceID es un identificador para el registro en sí, no para el registro digital de la misma. La mejor práctica recomendada es usar un identificador único global, también conocido como GUID. En ausencia de un GUID, se puede crear un identificador único a partir de otros identificadores dentro del conjunto de datos. Existen herramientas en internet que pueden ayudarle a generar GUID para sus registros. Si utiliza este método, estos GUID deberían convertirse en un campo permanente dentro de sus datos de origen que identifique cada registro. Para la práctica de este curso, creará un occurrenceID con un formato similar al tercer ejemplo que se muestra en el recuadro azul.

Diapositiva 15 - Extensiones Darwin Core
Al usar Simple Darwin Core, es posible que descubra que tiene más datos para compartir, pero no encuentra los términos correspondientes en DwC. Estos datos podrían ser archivos de imagen o sonido, o quizás sea responsable de una colección de vertebrados y tenga datos extensos recopilados sobre el peso y el tamaño de los especímenes. O incluso información histórica detallada sobre la identificación de un taxón. En estos casos, deberá recurrir a las extensiones de Darwin Core para ampliar los datos base proporcionando archivos adicionales que se correspondan con ellos. Las extensiones que se ajustan a sus necesidades en estos tres ejemplos son:
Mediciones Multimedia Simples o Historial de Identificación
Hay muchas más extensiones. GBIF mantiene una lista de todas las extensiones aprobadas y en borrador en su subsitio de herramientas.
Foto: Aleuria aurantia (Pers.) Fuckel observada en Nepal por Elizabeth Byers http://creativecommons.org/licenses/by-nc/4.0/
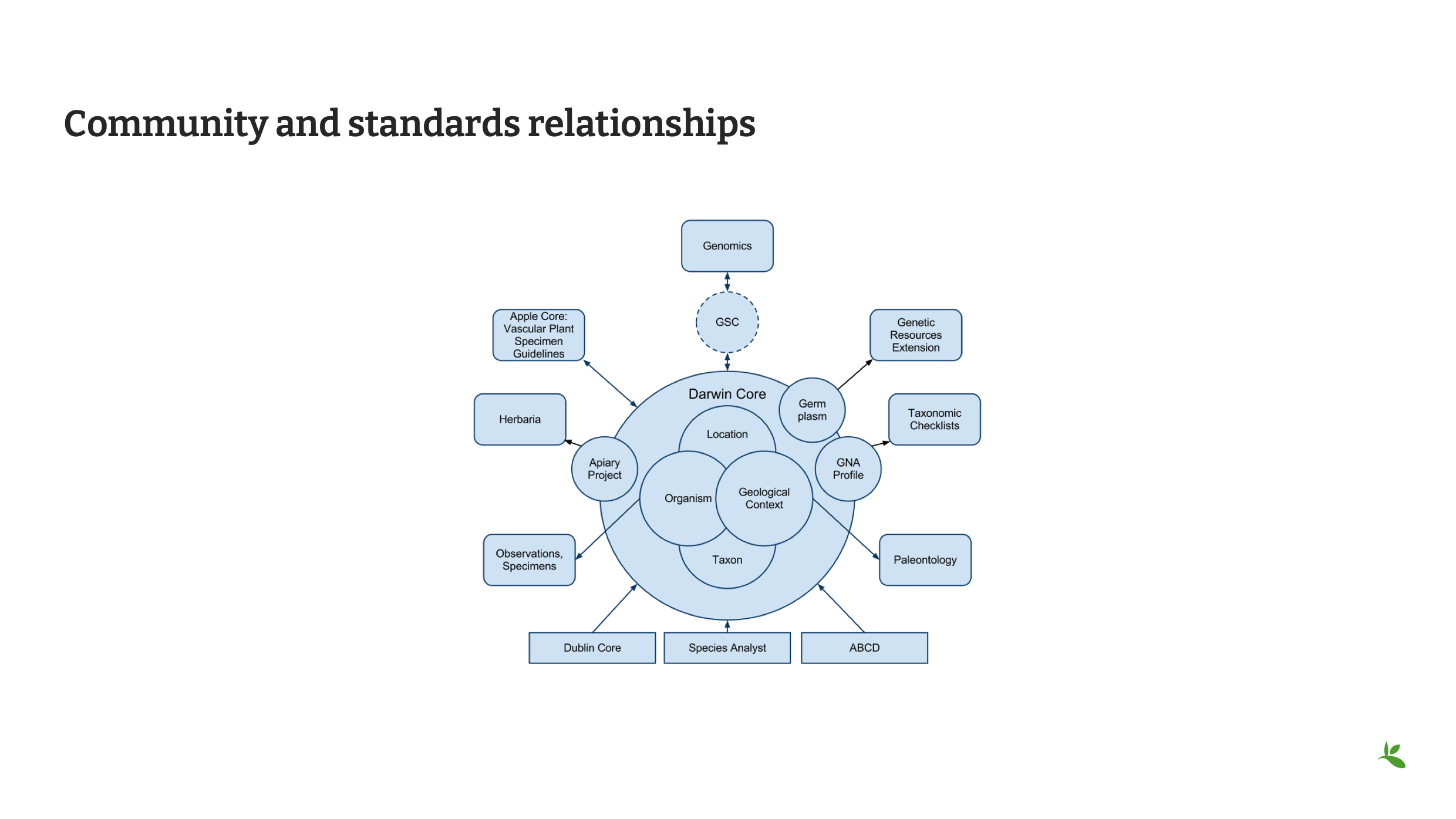
Diapositiva 16 - Relaciones entre la Comunidad y los estándares
Nuestra comunidad de bioinformática se compone de múltiples niveles. La imagen muestra las relaciones entre estos niveles, sus intersecciones con Darwin Core y las posibles extensiones necesarias para compartir datos de forma integral.
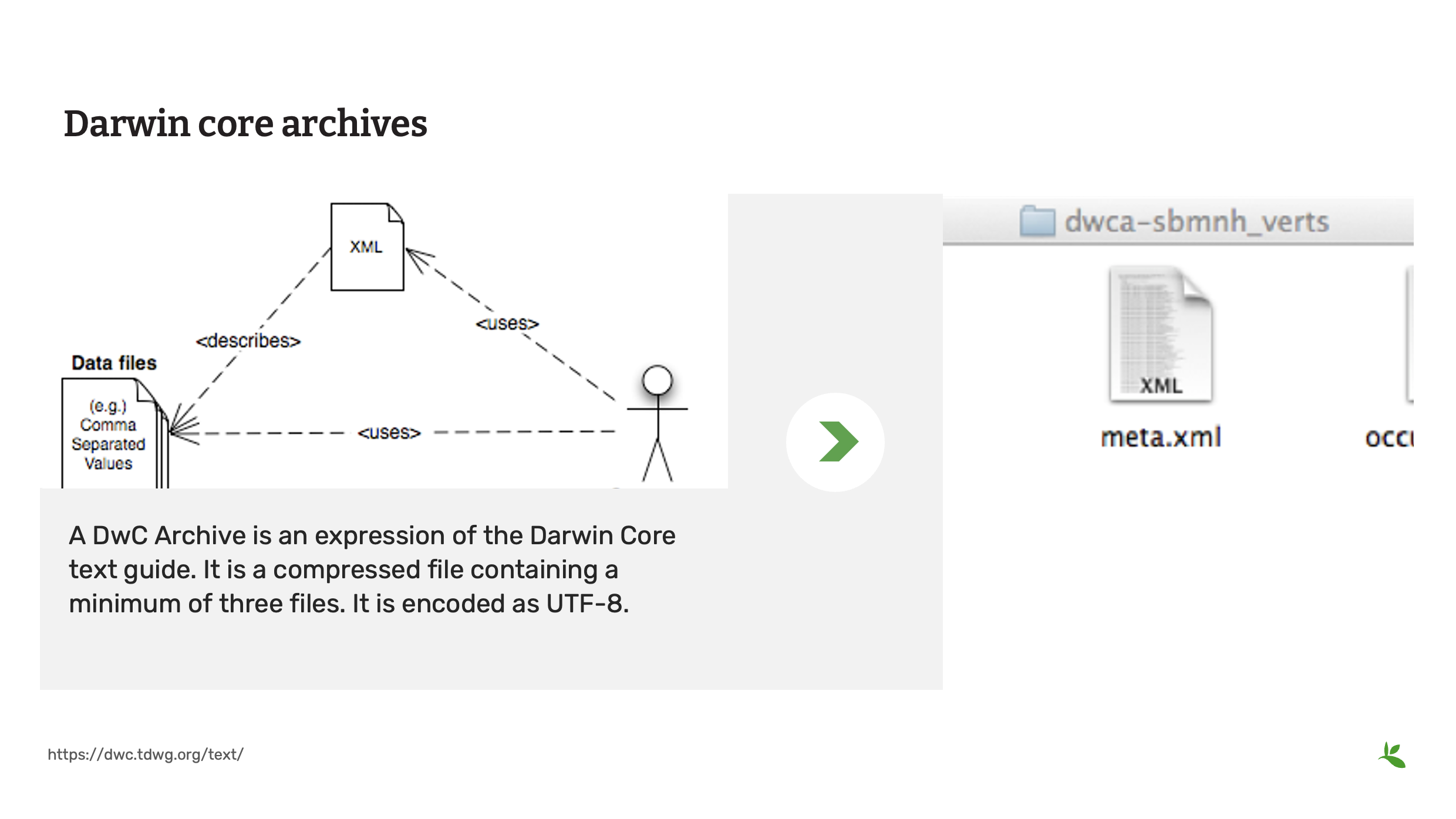
Diapositiva 17 - Archivos de Darwin Core (DwC-A)
Los datos compartidos con GBIF se envían a través de un Archivo de Darwin Core o DwCA.
Un DwCA es una expresión de la guía de texto de Darwin Core. Es un archivo comprimido que contiene un mínimo de tres archivos. Está codificado como UTF-8.
En este ejemplo, estos tres archivos son:
Un archivo de datos (occurrence.txt) conforme al SIMPLEDWC en formato CSV en el que la primera fila incluye los nombres de los términos estándar Darwin Core. Un archivo meta (meta.xml) en formato XML que contenga detalles técnicos para instruir a una computadora sobre cómo utilizar el archivo de datos. Un metafichero (eml.xml) en formato XML que contenga detalles explicativos sobre los registros contenidos en el fichero de datos para indicar a un usuario si los datos serán adecuados para su uso.
Una estructura más compleja se puede obtener compartiendo múltiples archivos csv relacionados para extender los datos. Están relacionados con el archivo del núcleo a través de un id único. En un conjunto de datos de registros biológicos, estos archivos csv relacionados están relacionados por el identificador del registro (occurrenceID).

Diapositiva 18 - Actualizaciones de DwC y paso al Darwin Core Data Package (DwC-DP)
Así, mientras que los Archivos Darwin Core han sido nuestro método preferido de publicación desde 2012, nos acercamos a un nuevo modelo llamado Paquete de Datos Darwin Core.
El nuevo modelo pretende "ampliar el abanico de cuestiones científicas que puede abordar GBIF."
It will allow us to expand our data scope, engage with new data communities, and build tools to enable data flows based on the updated standard.
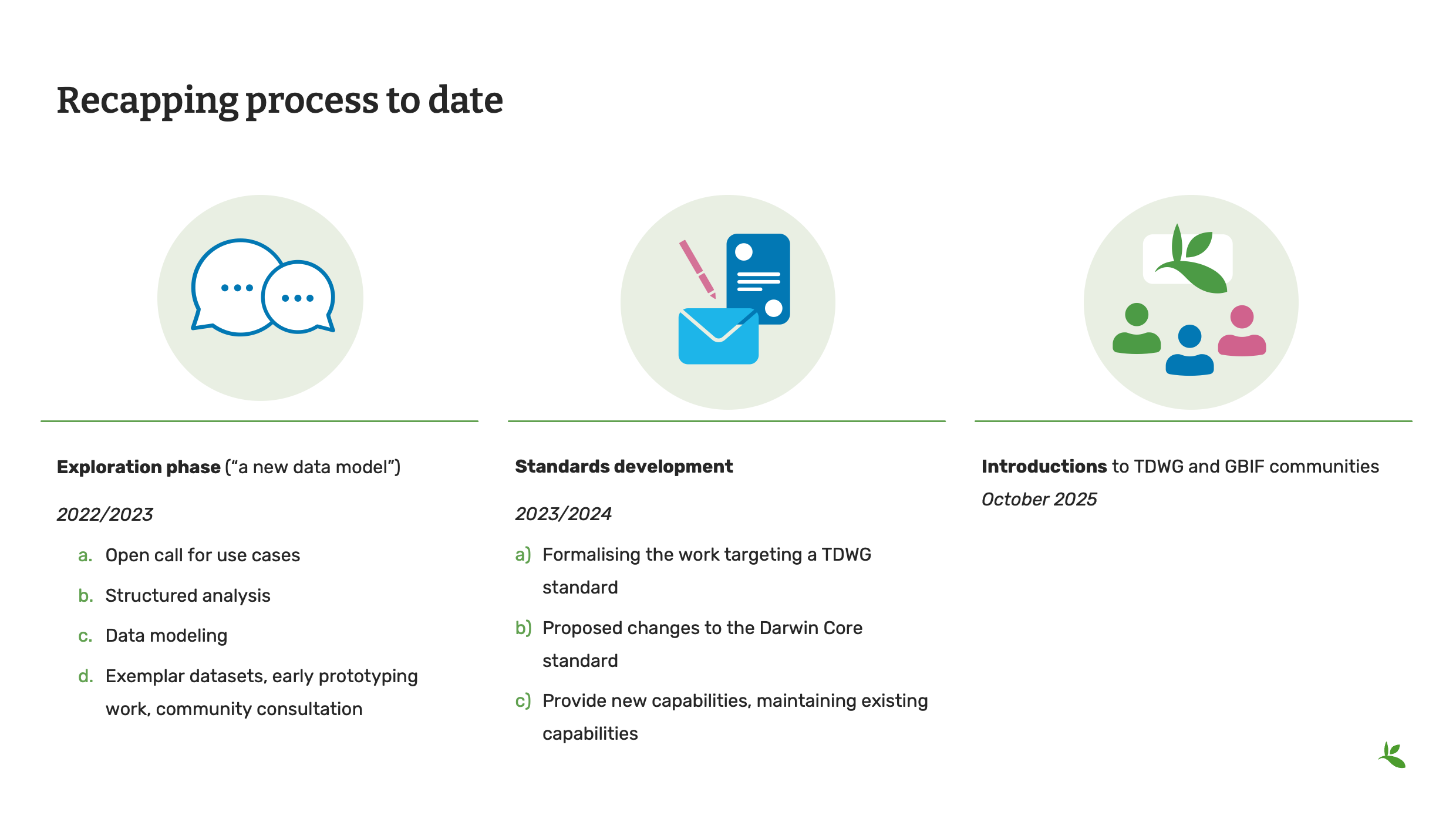
Diapositiva 19 - Recapitulación del proceso hasta la fecha
La comunidad ha estado desarrollando el trabajo sobre este modelo desde 2022 y los desarrollos de estándares para este modelo han estado en desarrollo desde 2023.
We are finally in the community review and ratification phase for the new terms and the new data package which was released in October of 2025. As you can see from this timeline, it takes a long time implement change to an established standard and it takes a dedicated community to see it through.

Diapositiva 20 - Cambios propuestos en Darwin Core
Los cambios sometidos a examen público incluyen:
65 nuevos términos 75 cambios propuestos a los términos existentes Un modelo conceptual documentado para DwC Directrices para el uso del Formato de Datos sin Fricciones
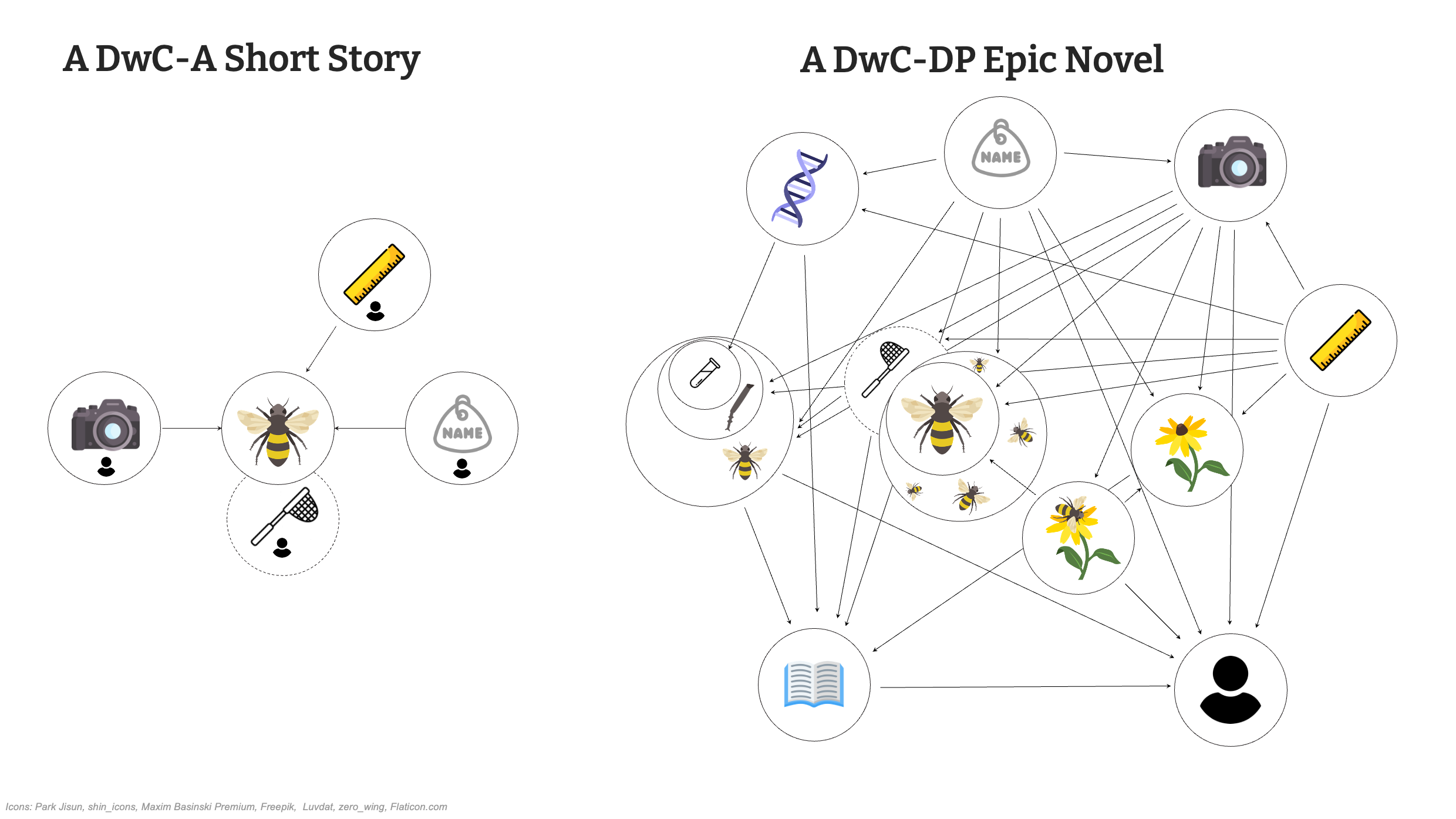
Diapositiva 21 - ¿Un relato corto de DwC-A o una novela épica de DwC-DP?
El Paquete de Datos Darwin Core abre completamente la posibilidad de compartir datos, convirtiendo un relato corto del Archivo Darwin Core en una novela épica del Paquete de Datos Darwin Core.
A modo de comparación, se pueden contar historias tanto con DwC-A como con DwC-DP, pero debería ser evidente que la gama de esfuerzos científicos que puede capturar fielmente DwC-DP es mucho más amplia.
Abeja, flor: Park Jisun DNA: Luvdat Libro: zero_wing Red: shin_icons Persona: Maxim Basinski Premium Tubo de ensayo: Freepik Regla: Freepik Cámara: Freepik Identificación: Freepik

Diapositiva 22 - ¿Tengo que hacer todo eso?
Todo esto puede resultar abrumador cuando acaba de aprender sobre la movilización de datos, pero queremos que sepa que se avecinan cambios que, en función de tus datos, pueden ser muy emocionantes para Ud.
También reconocemos que no todo el mundo necesita hacer todo eso, sobre todo dentro de un mismo conjunto de datos, y los publicadores podrán utilizar sólo lo que necesiten.
Por el momento, en este curso nos centraremos en la formación mediante el núcleo de eventos, sobre el que aprenderás más en las próximas sesiones.
Cuando se haya completado el proceso de ratificación y estemos listos para que los publicadores empiecen a utilizar el Darwin Core Data Package, organizaremos entrenamientos virtuales comunitarios para complementar la formación.
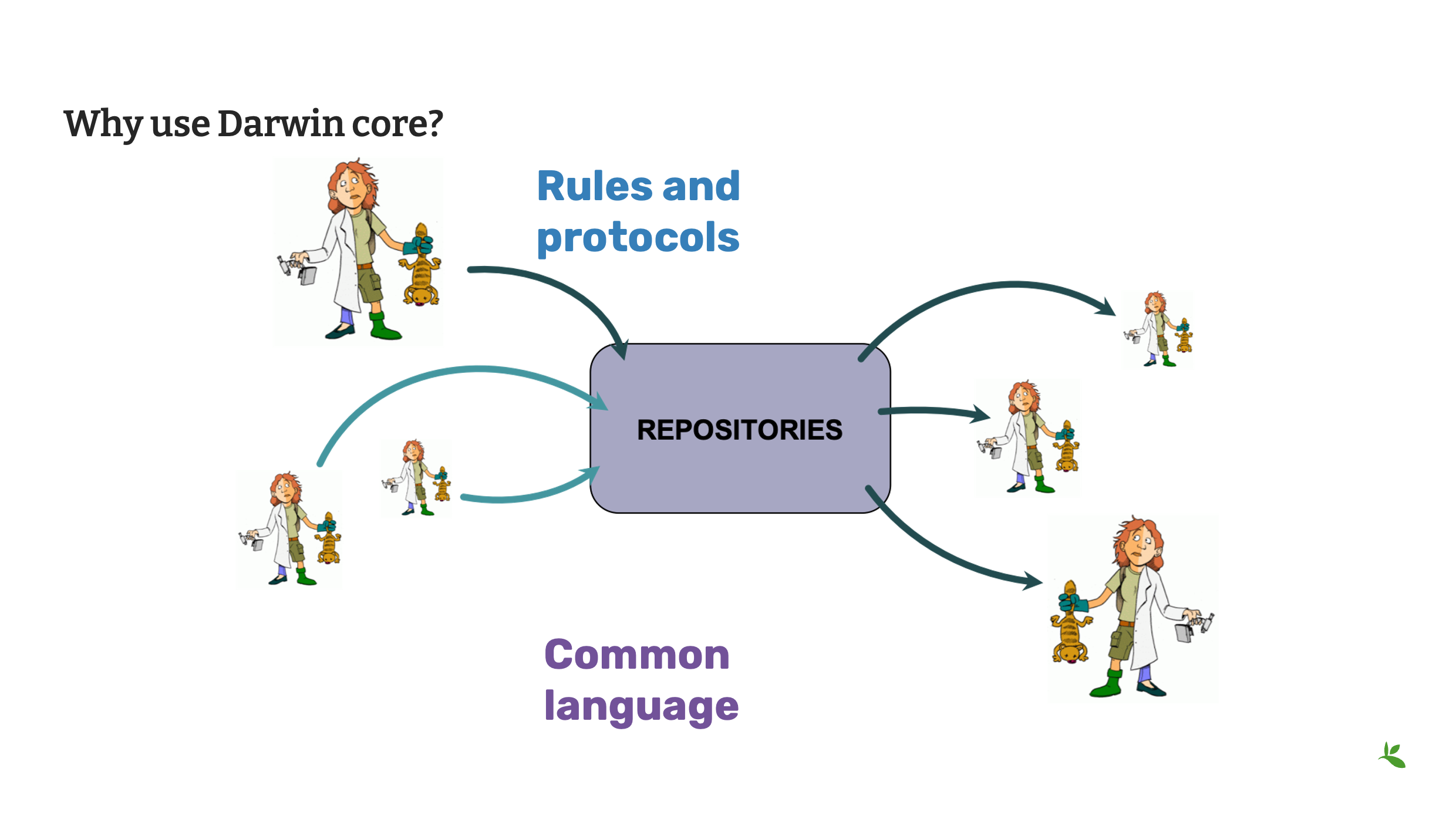
Diapositiva 23 - Qué es Darwin Core
Hemos cubierto lo Qué es Darwin Core y esperamos que haya comenzado a desarrollar una idea de por qué debería usarlo.
¡Es un estándar y los estándares son buenos! Los estándares nos brindan las reglas y protocolos que necesitamos para compartir nuestros datos con otros.
Darwin Core también nos proporciona un lenguaje común. Como vimos en los Fundamentos – Presentación de documentación, los datos de origen pueden resultar complicados al intentar comparar conjuntos de datos. Los campos en sus datos de origen pueden ser diferentes a los campos de otras instituciones fuente de datos. Cuando todos usamos Darwin Core para compartir nuestros datos, entendemos que los datos han sido compartidos con un idioma común.
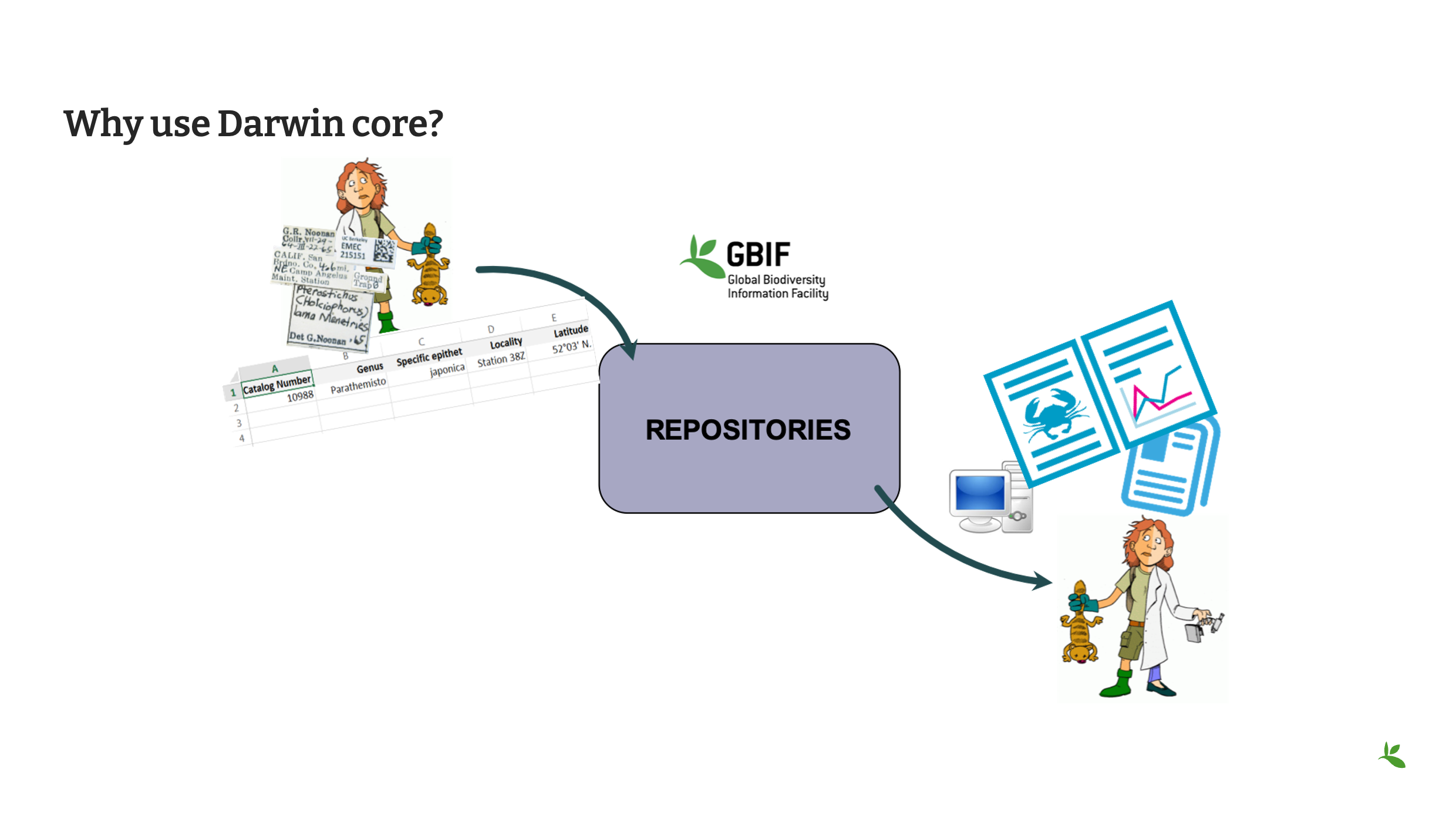
*Diapositiva 24: ¿Por qué utilizar Darwin Core
Y no solo los custodios de datos entienden este lenguaje común, sino también los usuarios de datos. Y después de todo, qué podría ser mejor que un usuario encuentre un conjunto de datos que sea adecuado para su uso compartido, en un lenguaje común, que le permita hacer mejor ciencia.

Diapositiva 25 - Conclusión
Esta presentación forma parte de una serie de presentaciones utilizadas en el curso de Movilización de Datos de Biodiversidad del GBIF. El programa de estudios sobre movilización de datos de biodiversidad se desarrolló originalmente como parte del Programa de Desarrollo de Información sobre Biodiversidad, financiado por la Unión Europea. Esta presentación fue creada originalmente por Paula Zermoglio y John Wieczorek, con contribuciones adicionales de Sharon Grant, Sophie Pamerlon, Laura Anne Russell, Cecilie Svenningsen y Dag Endresen. La narración es mía, Vijay Barve.
Ejercicio 1a
|
En esta actividad, examinará los nombres literales de los campos y los relacionará con los términos de Darwin Core |
-
Busque el término Darwin Core en https://dwc.tdwg.org/terms/ que mejor se adapte a los nombres de los campos.
-
Descargar UC-Ficha-ejercicio-práctica_EN.docx para proporcionar sus respuestas.
Tipos de conjuntos de datos de GBIF para datos primarios sobre biodiversidad
|
En este vídeo (08:16), revisará datos primarios de biodiversidad que se pueden compartir dentro de GBIF. Este vídeo aún no tiene subtítulos. Si no puede ver el vídeo incrustado, puede descargarlo localmente (MP4 - 28,8 MB)download (MP4 - 28.8 MB) Si prefieres leer, encontrarás la transcripción debajo del vídeo incrustado. |
Transcripción de la presentación
Haga clic para ampliar

Diapositiva 1 - Tipos de datos de GBIF para datos primarios sobre biodiversidad
En esta presentación, analizaremos los diferentes tipos de datos que se pueden denominar «datos primarios de biodiversidad» y que se comparten en GBIF. Estos datos pueden ser complejos y tener distintos orígenes. Veremos cómo se pueden estructurar en una de las clases de conjuntos de datos aceptadas por GBIF.
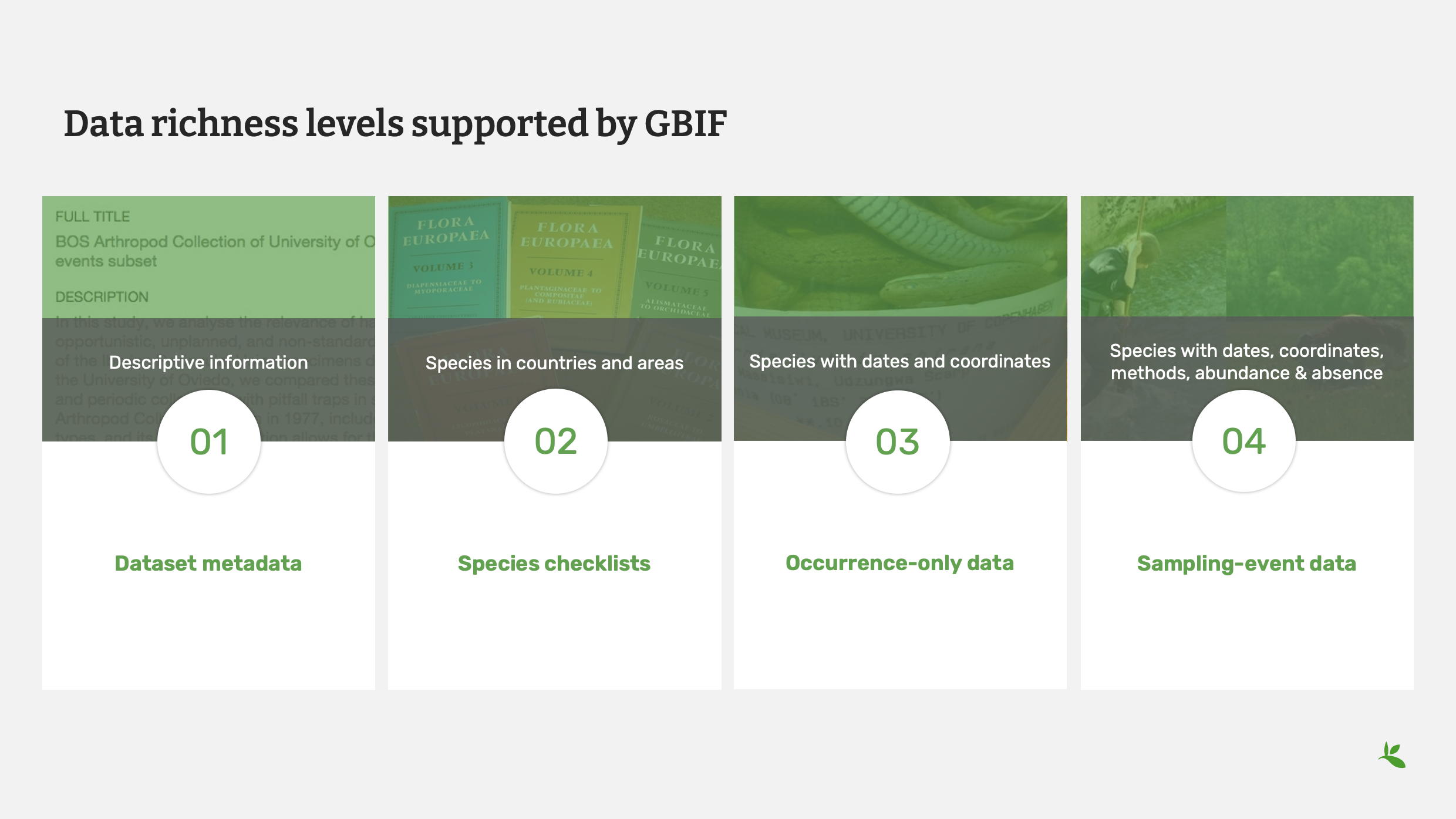
Diapositiva 2 - Niveles de riqueza de datos soportados por GBIF
GBIF admite actualmente cuatro tipos de conjuntos de datos:
El primero son los metadatos de los conjuntos de datos.
Este es un conjunto de datos que permite proporcionar información descriptiva sobre un conjunto de datos. Puede utilizar este tipo cuando aún no haya digitalizado sus datos. Con este tipo de conjunto de datos no se publican archivos de datos, solo metadatos descriptivos.
El segundo tipo son las listas de especies.
Esto te permite compartir información sobre las especies, incluyendo los países y las zonas donde se encuentran.
El tercer tipo son los datos de registros biológicos.
Este tipo de conjunto de datos es para datos que incluyen nombres, fechas y coordenadas: qué, cuándo y dónde se encuentran sus datos.
El último tipo es datos de monitoreo.
Este tipo te permite compartir aún más datos. Puedes compartir especies con fechas, coordenadas, métodos, abundancia e incluso ausencia.
A continuación exploraremos más a fondo los tipos de conjuntos de datos de lista de especies, registros biológicos y datos de monitoreo.

Diapositiva 3 - Datos de Evento de Muestreo
Los listados de especies proporcionan un catálogo o lista de organismos identificados, o taxones. Si bien pueden incluir detalles adicionales como nombres de especies locales o citas de especímenes, estas listas suelen categorizar la información según criterios taxonómicos, geográficos y temáticos, o una combinación de los tres. Por ejemplo, un listado de especies que cataloga los moluscos de Seychelles incluidos en la Lista Roja presenta elementos distintivos de taxonomía (el filo Mollusca), geografía (la nación insular de Seychelles) y temática (especies consideradas en peligro por los expertos de la UICN). Las listas de verificación funcionan como un resumen rápido o un inventario básico de taxones en un contexto determinado.

Diapositiva 4 - Plantilla GBIF para datos de taxones
GBIF proporciona a los editores de datos plantillas para cada tipo de conjunto de datos. La plantilla de GBIF para datos taxonómicos permite compartir información vinculada a cada especie o taxón, incluyendo el identificador, el nombre completo y la autoría, la relación con otros taxones, detalles geográficos, etc. En esta plantilla, cada línea representa un taxón, y cada taxón solo puede aparecer una vez en el conjunto de datos.
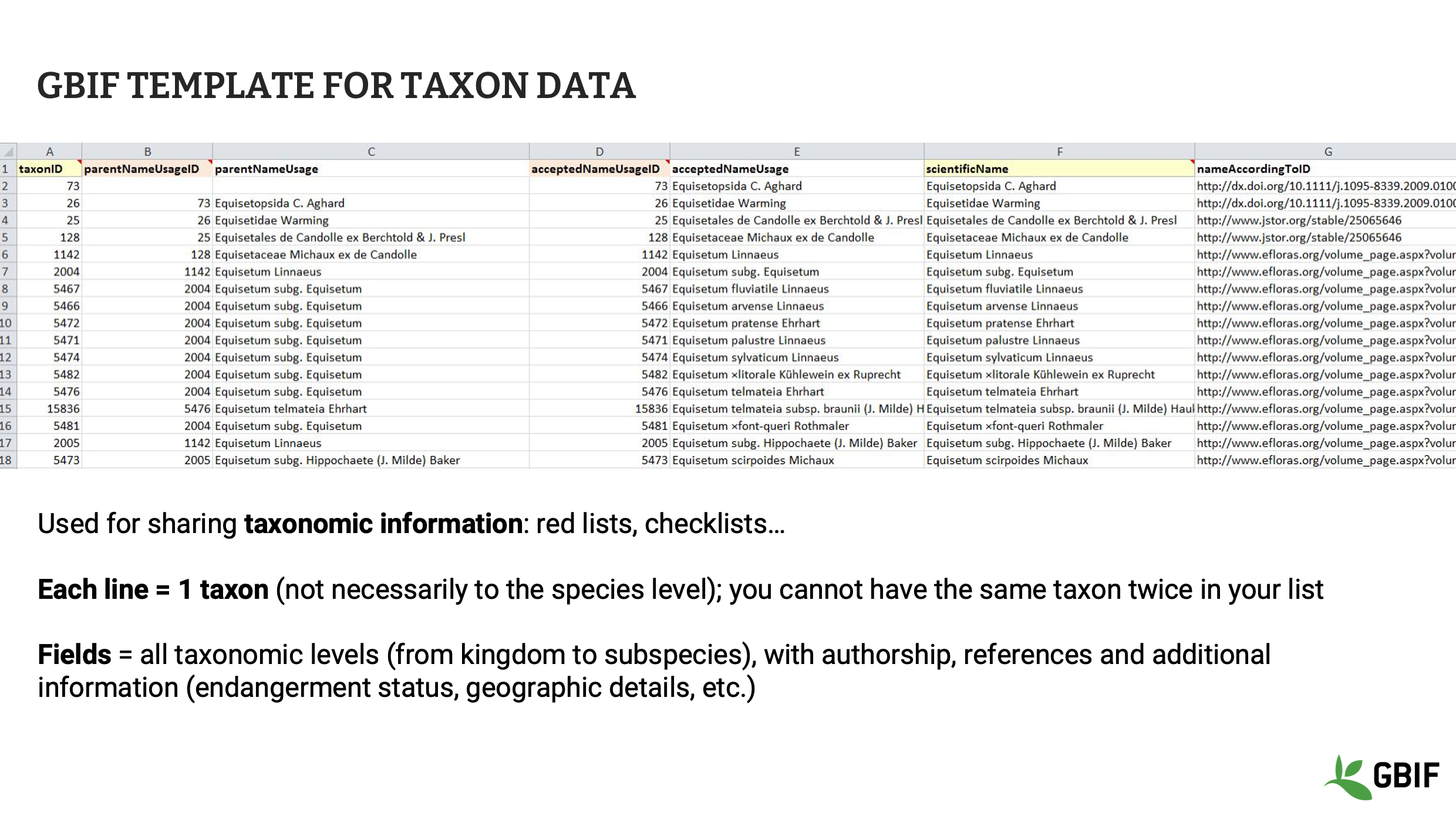
Diapositiva 5 - Registro biológico
Otros conjuntos de datos publicados a través de GBIF.org tienen un nivel de detalle suficientemente consistente como para aportar información sobre la ubicación de organismos individuales en el tiempo y el espacio; es decir, ofrecen evidencia de la presencia de una especie (u otro taxón) en un lugar determinado en una fecha específica.
Los conjuntos de datos de registros biológicos constituyen la base de los datos publicados a través de GBIF.org, y los ejemplos pueden abarcar desde especímenes y fósiles en colecciones de historia natural, observaciones de investigadores de campo y científicos ciudadanos, hasta datos recopilados mediante cámaras trampa o satélites de teledetección.
En ocasiones, los registros biológicos en estos conjuntos de datos solo proporcionan información general sobre la localidad, a veces simplemente identifican el país, pero en muchos casos, las ubicaciones y coordenadas geográficas más precisas permiten realizar análisis a pequeña escala y elaborar mapas de la distribución de las especies.

Diapositiva 6 - Registros biológicos en la literatura
Los datos sobre biodiversidad también pueden encontrarse en la literatura técnica y científica: es posible recopilar y compartir este tipo de datos dentro de GBIF, pero se debe tener especial cuidado de no compartir datos duplicados (por ejemplo, un espécimen descrito en un artículo científico podría estar ya presente en GBIF.org en el conjunto de datos de su colección)
En ausencia de conjuntos de datos digitalizados, los datos de biodiversidad pueden extraerse y recopilarse de artículos científicos, tesis doctorales o de maestría, informes y otros documentos. SIEMPRE contacte primero con el propietario de los datos al recopilar información bibliográfica para solicitar permiso para publicarla en GBIF.

Diapositiva 7 - Plantilla GBIF para datos de registros biológicos
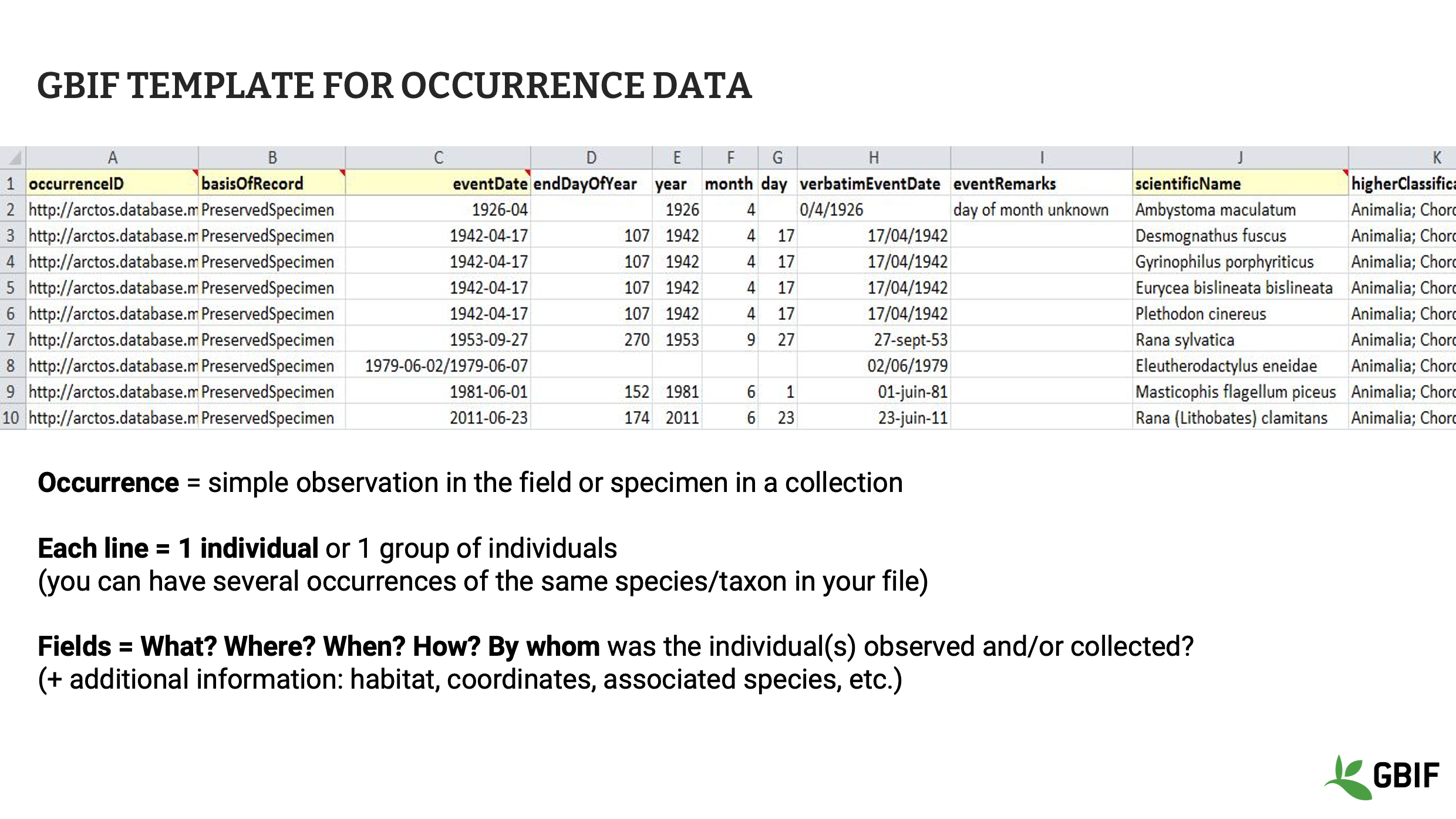
Los datos de registro biológico representan la clase de conjuntos de datos de GBIF con el mayor número de registros en GBIF.org. Las colecciones, observaciones y datos bibliográficos pueden compartirse dentro de GBIF mediante esta plantilla, que se centra en los individuos observados o los especímenes recolectados. En este tipo de conjunto de datos, se pueden registrar varios individuos o especímenes para un mismo taxón, siempre que cada uno tenga un identificador único. Otros campos para los datos de ocurrencia incluyen dónde, cuándo, cómo y quién observó o recolectó cada registro en el campo.

Diapositiva 8 - Muestreo de datos de eventos
En ocasiones, los conjuntos de datos proporcionan información más detallada, no solo aportando pruebas de la presencia de una especie en una fecha y lugar determinados, sino también permitiendo evaluar la composición de la comunidad para grupos taxonómicos más amplios o incluso la abundancia de especies en diferentes momentos y lugares. Estos conjuntos de datos cuantitativos o de muestreo suelen derivarse de protocolos estándar para la medición y el seguimiento de la biodiversidad, como transectas de vegetación, censos de aves y muestreos de agua dulce o marina.
Al indicar los métodos, los muestreos y la abundancia relativa de las especies registradas en una muestra, estos conjuntos de datos mejoran las comparaciones con los datos recogidos con los mismos protocolos en momentos y lugares diferentes, y en algunos casos incluso permiten a los investigadores deducir la ausencia de determinadas especies en lugares concretos.

Diapositiva 9 - Plantilla GBIF para datos de eventos de muestreo
La plantilla GBIF para datos de muestreo permite a los publicadores de datos compartir más información sobre el contexto de un evento de recolección/registro de datos de biodiversidad, como trampas fotográficas, trampas para insectos, relevamientos botánicos, sitios de observación de aves, etc. Su estructura es más compleja que la de los conjuntos de datos taxonómicos y de registros biológicos, ya que implica al menos dos archivos (p. ej., dos pestañas en una hoja de cálculo): uno para describir los "eventos" (p. ej., cada trampa) y otro para describir los especímenes o registros vinculados a cada evento. Puede haber archivos/pestañas adicionales para describir mediciones o datos, o para proporcionar más detalles sobre los protocolos de muestreo.

Diapositiva 10 - Tipos de conjuntos de datos y requisitos de calidad de los datos
Los requisitos de calidad de datos de GBIF describen lo que debe proporcionar para cada clase de conjunto de datos. Esto no significa que los datos no serán indexados si faltan algunos valores, pero estos requisitos resumen lo que se puede considerar información significativa para cada clase. Por supuesto, puede aportar más.
Algunos requisitos son obligatorios (como el occurrenceID, taxonID o eventID, dependiendo del tipo de conjunto de datos), otros son opcionales pero muy recomendables (como las coordenadas en grados decimales). Puede encontrar estos requisitos en GBIF.org.

Diapositiva 11 - ¿Cómo elegir un tipo de conjunto de datos?
Elegir una clase de conjunto de datos puede llevar tiempo, sobre todo si es nuevo en la publicación de datos en GBIF. El Helpdesk de GBIF creó este útil diagrama de flujo, que puedes encontrar en el Blog de Datos de GBIF si necesitas más ayuda para decidir.
Diapositiva 12 - Reflexión
Para poder publicar datos en GBIF, es importante comprender las diferencias entre las clases de conjuntos de datos en las primeras etapas del proceso de captura y gestión de datos. Puede reflexionar sobre este tema con las siguientes preguntas:
¿Con qué tipo de datos trabajas?
¿El tipo de datos es diferente al que pensabas inicialmente?
¿Cómo los publicaría en GBIF?

Diapositiva 13 - Conclusión
Esto forma parte de una serie de presentaciones utilizadas en el curso de Movilización de Datos de Biodiversidad del GBIF. El programa de estudios sobre movilización de datos de biodiversidad se desarrolló originalmente como parte del Programa de Desarrollo de Información sobre Biodiversidad, financiado por la Unión Europea.
Esta presentación fue creada originalmente por Sophie Pamerlon con contribuciones adicionales de Laura Anne Russell y Entrenadores y Mentores de GBIF. Esta presentación fue narrada por mí, Laura Anne Russell.
Captura, procesamiento y calidad de datos
|
En este vídeo (12:06), explorará los principios de la calidad de los datos aplicados a la captura de datos, concretamente cuando se capturan datos de etiquetas de especímenes, cuadernos de trabajo de campo, hojas de cálculo, etc. Si no puede ver el vídeo incrustado, puede descargarlo localmente. download Los subtítulos aún no están disponibles para este vídeo. (MP4 - 42 MB) Si prefieres leer, encontrarás la transcripción debajo del vídeo incrustado. |
Transcripción de la presentación
Haga clic para ampliar

Diapositiva 1 - Captura, procesamiento y calidad de los datos
Esta presentación se basa en "Principios para la calidad de los datos" de Arthur Chapman

Diapositiva 2 - Estructura
Durante esta presentación, exploraremos los principios de calidad de datos aplicados a la captura de datos, específicamente al capturar datos de etiquetas de colecciones, cuadernos de campo, hojas de cálculo, etc.

Diapositiva 3 - Desarrollar un flujo de trabajo para el procesamiento y la calidad de los datos
La calidad de los datos es fundamental en cada etapa del proceso de movilización de datos, especialmente en las etapas de captura de datos.
Cada persona implicada en la captura de datos tiene su parte de responsabilidad en lo que respecta a la calidad de los datos, pero la mayoría de las decisiones sobre este tema deben tomarse a nivel institucional.
Las palabras clave aquí son: ¡planificación y documentación!
Como se mencionó en la presentación de la documentación de Fundamentos, utilice los estándares existentes y planifique sus flujos de trabajo para que coincidan con sus objetivos; documente todo lo que pueda, en cada paso, y comparta o reutilice documentos, datos, herramientas y estándares tanto como sea posible.
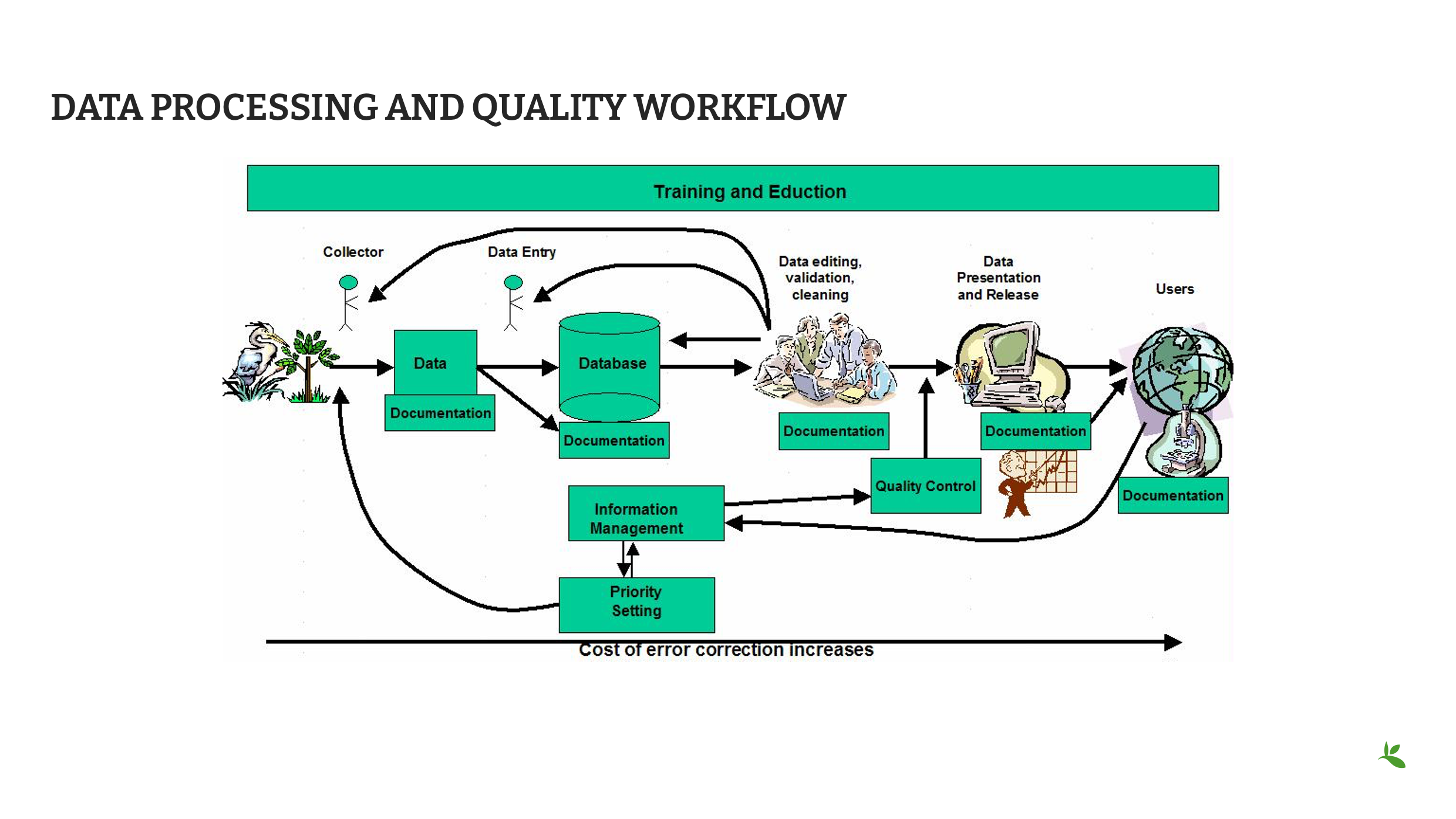
Diapositiva 4 - Flujo de trabajo de procesamiento y calidad de datos
Este es un ejemplo de un flujo de trabajo de calidad de datos.
En este flujo de trabajo, se comienza con la recolección de muestras, se pasa a la captura de datos, luego al control de calidad, la publicación y, finalmente, al uso.
La calidad de los datos no es responsabilidad exclusiva de la primera persona que interviene en el proceso (en este caso, el recolector); es una responsabilidad compartida en cada etapa, y todas las personas que participan en el proceso deben tener una responsabilidad en cuanto a la calidad.
Es necesario contar con un sistema de retroalimentación que funcione correctamente para verificar, completar, actualizar o corregir los datos.
Aquí es donde la documentación resulta esencial: es necesario saber quién fue el responsable de cada paso del proceso para poder validar los cambios que se han realizado en los datos (o que deben realizarse).

Diapositiva 5 - Responsabilidades en materia de procesamiento y calidad de datos
En esta vista simplificada del flujo de datos, puede ver algunas de las responsabilidades en materia de calidad de datos de cada grupo de personas implicadas.
En este ejemplo, el equipo encargado de la movilización se puede dividir en los roles de "transcriptores" y "curadores".
El equipo de transcriptores debe asegurarse de que los datos se capturen y guarden de la mejor manera posible, mientras que el rol de "curador" tiene la responsabilidad última de garantizar que cada equipo cumpla con sus funciones en el proceso.
Imagen del colector: https://pixabay.com/fr/photos/d%C3%A9tective-loupe-regarde-un-788592/
Imagen de usuario: www,gbif.org (Resultados de la búsqueda del conjunto de datos de cámaras trampa de WSC Camboya)
Imágenes del curador: https://pixabay.com/fr/photos/livres-livres-anciens-ordinateur-4802412/ & https://pixabay.com/fr/photos/donn%C3%A9es-ordinateur-internet-2899901/

Diapositiva 6 - Estructura
Una vez establecido el flujo de trabajo de datos, puede comenzar la captura de datos propiamente dicha.
En las siguientes diapositivas, exploraremos los distintos tipos de información que pueden obtenerse a partir de especímenes u observaciones de campo, y veremos cuáles son los errores más comunes que deben evitarse al tratar cada tipo de información.
Los temas principales serán los siguientes: información taxonómica, información espacial, información sobre colecciones, información descriptiva.
Tenga en cuenta que cada registro biológico (cada fila de su base de datos u hoja de cálculo) debe tener información vinculada a estos 4 temas principales para poder compartirla y reutilizarla como corresponde.

Diapositiva 7 - Información taxonómica: vocabularios y conceptos
La información taxonómica es una parte esencial del proceso de captura de datos.
Sin ella, un espécimen digitalizado es inútil y no puede interpretarse ni reutilizarse correctamente.
Hay que tener en cuenta que el nombre de la especie no es el único tipo de información taxonómica que se puede aprovechar en el proceso de captura de datos: a veces, el espécimen no se ha identificado hasta la especie, y los niveles taxonómicos superiores, como el género o la familia, siguen siendo útiles para los gestores y usuarios de datos.

Diapositiva 8 - Información taxonómica: ¡cuidado con los nombres!
La mayoría de las veces, el nombre científico es la principal forma de recuperar datos en una base de datos, portal, sitio web, navegador, etc.
Cualquier error ortográfico o de autoridad puede dar lugar a consultas erróneas o nulas, lo que obstaculiza la gestión y la posible reutilización de los datos.
Por eso es muy importante comprobar todas las categorías de nombres científicos para corregir errores y/u omisiones.

Diapositiva 9 - Información taxonómica: errores comunes que deben evitarse
Los problemas más comunes que surgen con la información sobre taxones son la falta de información o la información incoherente, los valores incorrectos o no atómicos, los duplicados y la incertidumbre.
Consulte siempre las definiciones y ejemplos de términos taxonómicos Darwin Core para evitar errores de nomenclatura: http://rs.tdwg.org/dwc/terms/index.htm

Diapositiva 10 - Información espacial: vocabulario y conceptos
La información geográfica resulta valiosa en muchos contextos de reutilización de datos, como la modelización de nichos o los estudios sobre distribución de especies.
Aunque es comprensible que las colecciones o especímenes "antiguos" sean difíciles, si no imposibles, de geolocalizar con precisión, se recomienda compartir coordenadas precisas o información textual siempre que sea posible.
Las coordenadas deben registrarse directamente sobre el terreno cuando sea posible, junto con la incertidumbre y el datum geodésico utilizado. De lo contrario, utilice fuentes pertinentes y verificadas para geolocalizar sus datos.
Debe tener en cuenta que las coordenadas u otra información geográfica pueden generalizarse o incluso no compartirse en absoluto en algunos contextos, como en el de la conservación de especies sensibles.

Diapositiva 11 - Información espacial: ¿de qué estamos hablando?
La información espacial puede encontrarse en numerosos formatos, no sólo en coordenadas geográficas: algunos ejemplos son (aunque no exclusivamente) los datos de cuadrícula, punto+radio o polígonos.
Cada uno de ellos es útil compartirlo para comprobar la coherencia de los elementos geográficos (por ejemplo, coordenadas frente a código de país, o para asegurarse de que una localidad determinada es coherente con los viajes de un coleccionista)
Imagen de punto+radio: https://live.staticflickr.com/5820/23736048306_35dfd89c05_b.jpg
{kind=link}

Diapositiva 12 - Información espacial: algunas definiciones más
Dentro de GBIF, se recomienda compartir el Datum geodésico que se usó para derivar las coordenadas que se compartieron (latitud y longitud decimal).
En ausencia de un datum geodésico específico, GBIF inferirá WGS84 por defecto.

Diapositiva 13 - Información espacial: errores comunes que deben evitarse
Esta diapositiva muestra un antiguo mapa GBIF con diferentes tipos de problemas geográficos: el más obvio es un efecto espejo entre EE. UU. y China (coordenadas invertidas),
También se puede observar una línea artificial a lo largo del meridiano de Greenwich donde se pusieron valores "0" en el campo "decimalLongitude", así como otra en el Ecuador donde se pusieron valores "0" en el campo "decimalLatitude".
La indexación de GBIF incluye ahora comprobaciones geográficas automáticas entre las coordenadas y el countryCode compartidos dentro del conjunto de datos. Las coordenadas pueden invertirse automáticamente para que coincidan con el país.

Diapositiva 14 - Información de la colecta: vocabulario y conceptos
Es muy útil compartir información sobre el contexto de la colecta de datos o de la observación para dar el mayor detalle posible sobre cada registro biológico.
Información como el nombre del recolector, el protocolo de colecta u observación, el hábitat y otros factores pueden resultar importantes a la hora de reutilizar los datos, por ejemplo con la modelización de nichos ecológicos.
Dependiendo del tipo de conjunto de datos, también puede ser relevante otra información.
Crédito de la imagen: https://pixabay.com/fr/photos/tige-afrique-jumelles-bush-safari-863823/

Diapositiva 15 - Información sobre la colecta: aspectos a tener en cuenta
Los factores de calidad de los datos relativos a la información sobre la colecta se centran principalmente en la exactitud, como el nombre correcto del colector, la coherencia, por ejemplo utilizando el mismo vocabulario para describir los suelos y los hábitats, y la exhaustividad, por ejemplo proporcionando toda la información existente sobre la descripción de una especie determinada, incluido el periodo de floración, el color de las hojas y los usos medicinales.
Dentro de Darwin Core y del IPT se pueden encontrar vocabularios controlados recomendados para algunos campos, como el de "lifeStage". El grupo de trabajo de vocabularios del TDWG trabaja para promover y mejorar la facilidad de uso de los vocabularios.

Diapositiva 16 - Información descriptiva: vocabularios y conceptos
Tenga en cuenta que la información descriptiva suele estar incompleta debido a una gran variedad de factores.
Dependiendo del estado de la colección, algunas etiquetas pueden estar incompletas o carecer de información crucial; la exhaustividad (por ejemplo, de la descripción de una especie) es a menudo imposible de lograr con un solo individuo; y siempre debe comprobar la coherencia en su base de datos u hoja de cálculo, por ejemplo, en los términos utilizados para describir los colores, con el fin de evitar información redundante.
Crédito de la imagen: Conjunto de datos sobre la presencia de la polilla de Taiwán recopilados de redes sociales
{kind=link}

Diapositiva 17 - Resumen
Esta presentación se ha centrado en el tema de la calidad de los datos aplicada a la captura de datos; en efecto, se trata de los pasos en los que es crucial garantizar que toda la información relacionada con cada registro se captura de forma correcta y completa, para que los datos sean lo más claros y comprensibles posible para los futuros usuarios.
Esto sólo puede hacerse si se toman decisiones coherentes a nivel institucional para crear un flujo de trabajo sólido para la captura y gestión de datos.
La cadena de responsabilidad en cuanto a la calidad de los datos se divide entonces entre las personas implicadas en cada etapa del proceso, pero hay que tener en cuenta que los datos siempre pueden mejorarse y corregirse si se detectan errores u omisiones en etapas posteriores.

Diapositiva 18 - Conclusión
Esto forma parte de una serie de presentaciones utilizadas en el curso de Movilización de Datos de Biodiversidad del GBIF. El programa de estudios sobre movilización de datos de biodiversidad se desarrolló originalmente como parte del Programa de Desarrollo de Información sobre Biodiversidad, financiado por la Unión Europea.
Esta presentación fue creada y narrada originalmente por Sophie Pamerlon, con contribuciones adicionales de Entrenadores, Mentores y Participantes de BID y BIFA. La narración es mía, Lily Shrestha.
Ejercicio 1c
|
Para esta actividad, realizará un ejercicio de simulación de captura de datos de analógico a digital. Utilice los términos de Darwin Core que aparecen en Darwin Core terms para tomar decisiones sobre los datos necesarios para el proyecto y sobre lo que podría compartirse posteriormente en la publicación. |
-
Descargar UC-Practice-1-ForCapture-logs.zip. (939 KB). El archivo comprimido contiene tres archivos de registro.
-
Descargue la plantilla de hoja de cálculo: UC-Practice-1-ForCapture-template.xlsx (27 KB) para transcribir las observaciones registradas.
-
Utilice la hoja de ejercicios, previamente descargada, para proporcionar sus respuestas.
| puede añadir campos a la plantilla si cree que puede capturar más información de la prevista en la plantilla. |