Documentation
| This module provides information on the importance of documentation. |
|
In this video (09:47), we will provide an overview of the importance of documentation as it relates to data management and data publishing. You will learn about data mapping, data relationships and metadata. If you are unable to watch the embedded video, you can download it locally. (MP4 - 35.2 MB) |
Transcription de la présentation
Cliquez pour développer

Slide 1 - Foundations - Documentation
In this presentation, we will provide an overview of the importance of documentation as it relates to data management and data publishing. You will learn about data mapping, data relationships and metadata.

Slide 2 - Documentation
In the previous Foundations presentations, we looked at the individual elements that make up both your data and the containers that hold it. Now we’ll look at ways to document those data and what you want to do with it. According to the director Steven Spielberg, “People have forgotten how to tell a story. Stories don’t have a middle or an end any more. They usually have a beginning that never stops beginning.” (Steven Spielberg) Documentation is the story of your project or dataset. There should always be a concrete beginning, middle and end. In essence you should be able to answer certain questions at specific points: At the beginning : What did our project aim to do? What was the purpose of creating the dataset?
In the middle: What did we actually do? What did we achieve?
At the end: What didn’t we achieve? Why? What should happen next?
Slide 3 - Key concepts
In order to document your data and render them as fit for use as possible for yourself and future users, you need to follow these three essential steps:
-
Mapping your data to existing formats and standards if necessary
-
Planning your data moves
-
Create useful metadata describing your data
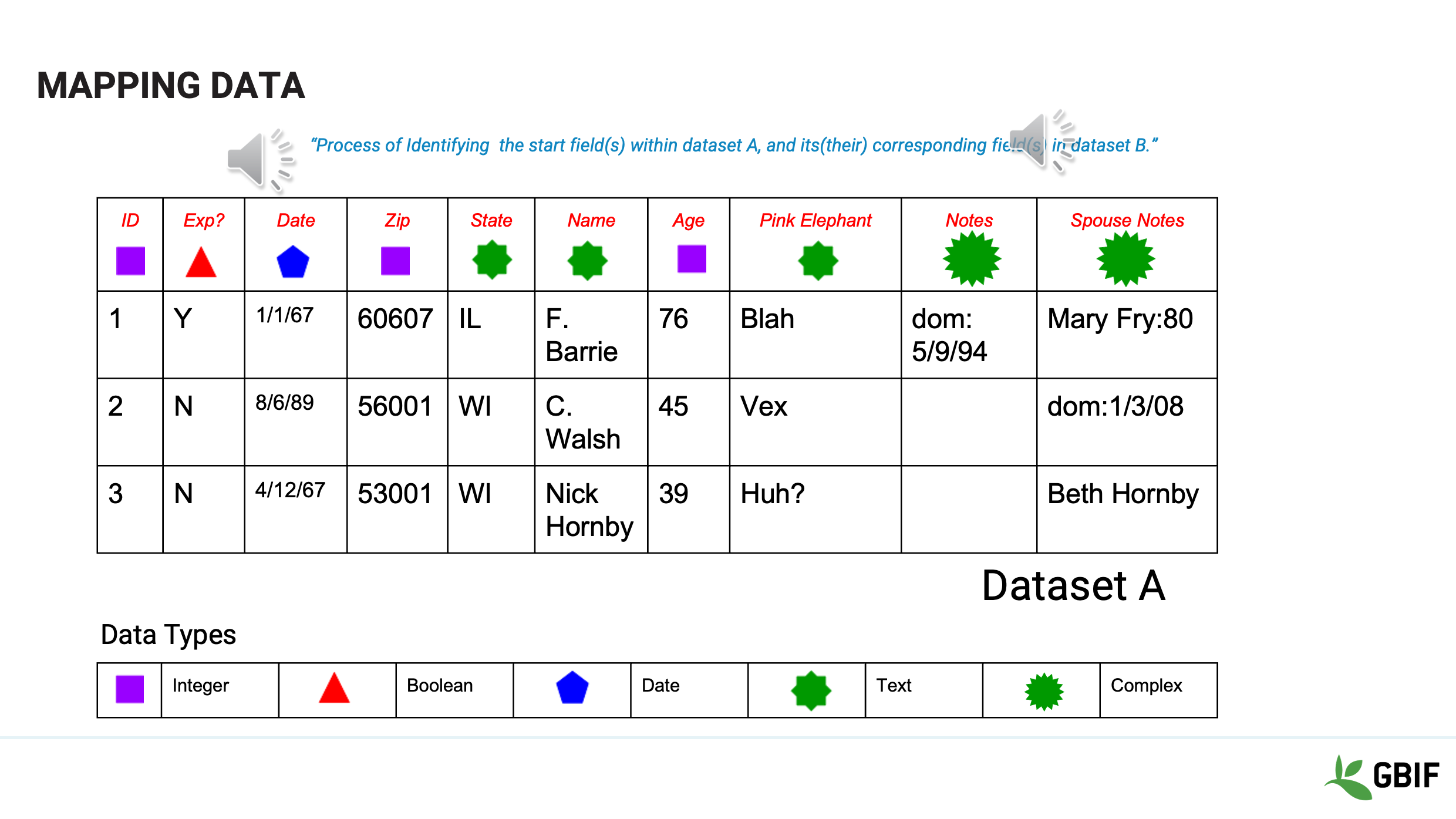
Slide 4 - Mapping data
We will begin by looking at ways to describe your data, then we will show how to map your data from one data structure to another and finally talk about how to record metadata about your data. First is mapping data. This is the process that you will use to describe how the attributes in your dataset can be transformed into attributes in a different one. Mapping data is the “Process of Identifying the start field(s) within dataset A, and its (their) corresponding field(s) in dataset B.” In this example Dataset A has 10 columns. There are: * some integer fields represented by the purple squares, * some boolean fields represented by the red triangles * some date fields represented by blue pentagons * some text fields, green 8 pointed stars * and some complex fields
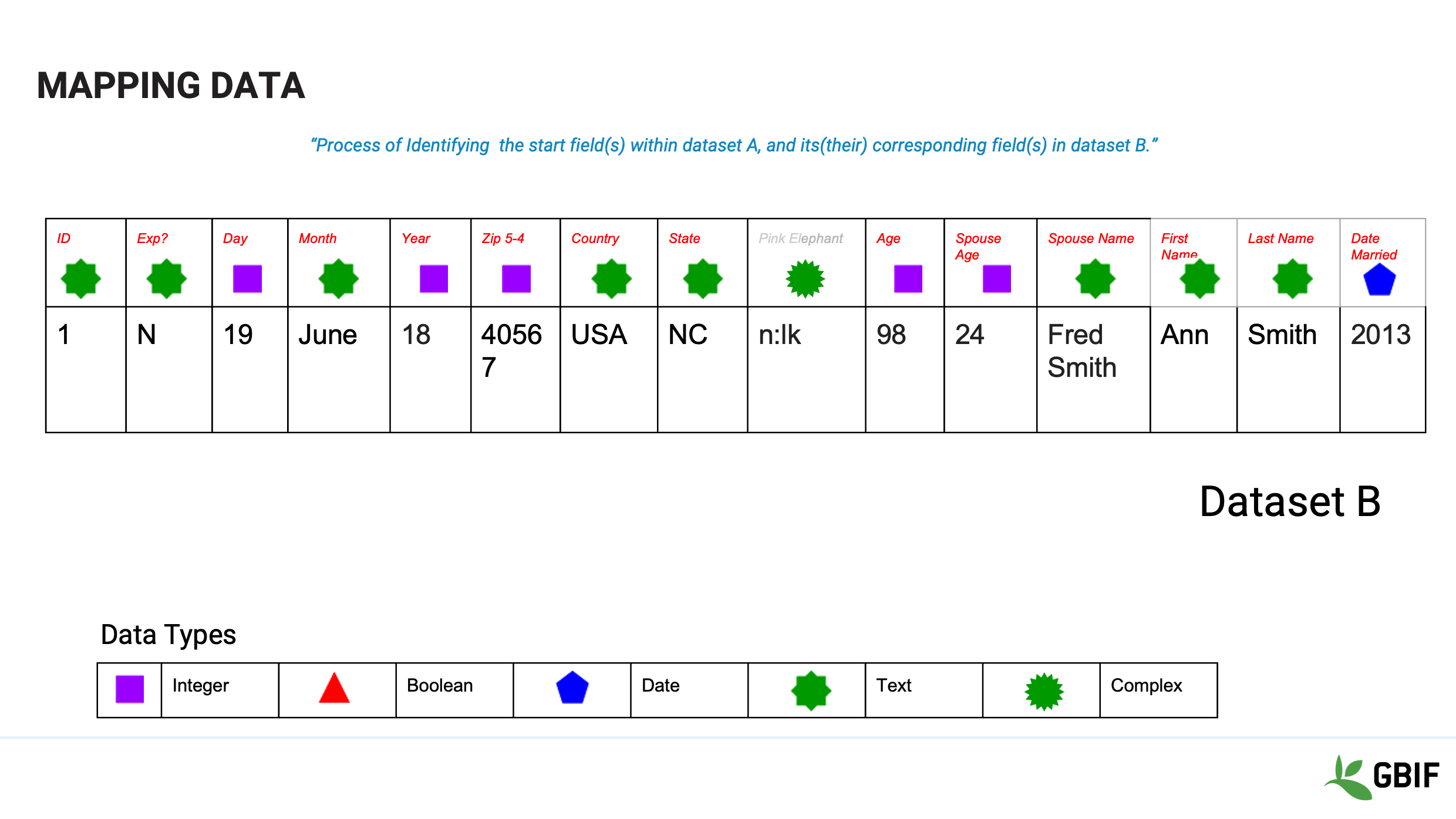
Slide 5 - Mapping data
Dataset B has a different set of fields, 15 in total. What we need to do is identify which fields in Dataset A match which fields in Dataset B
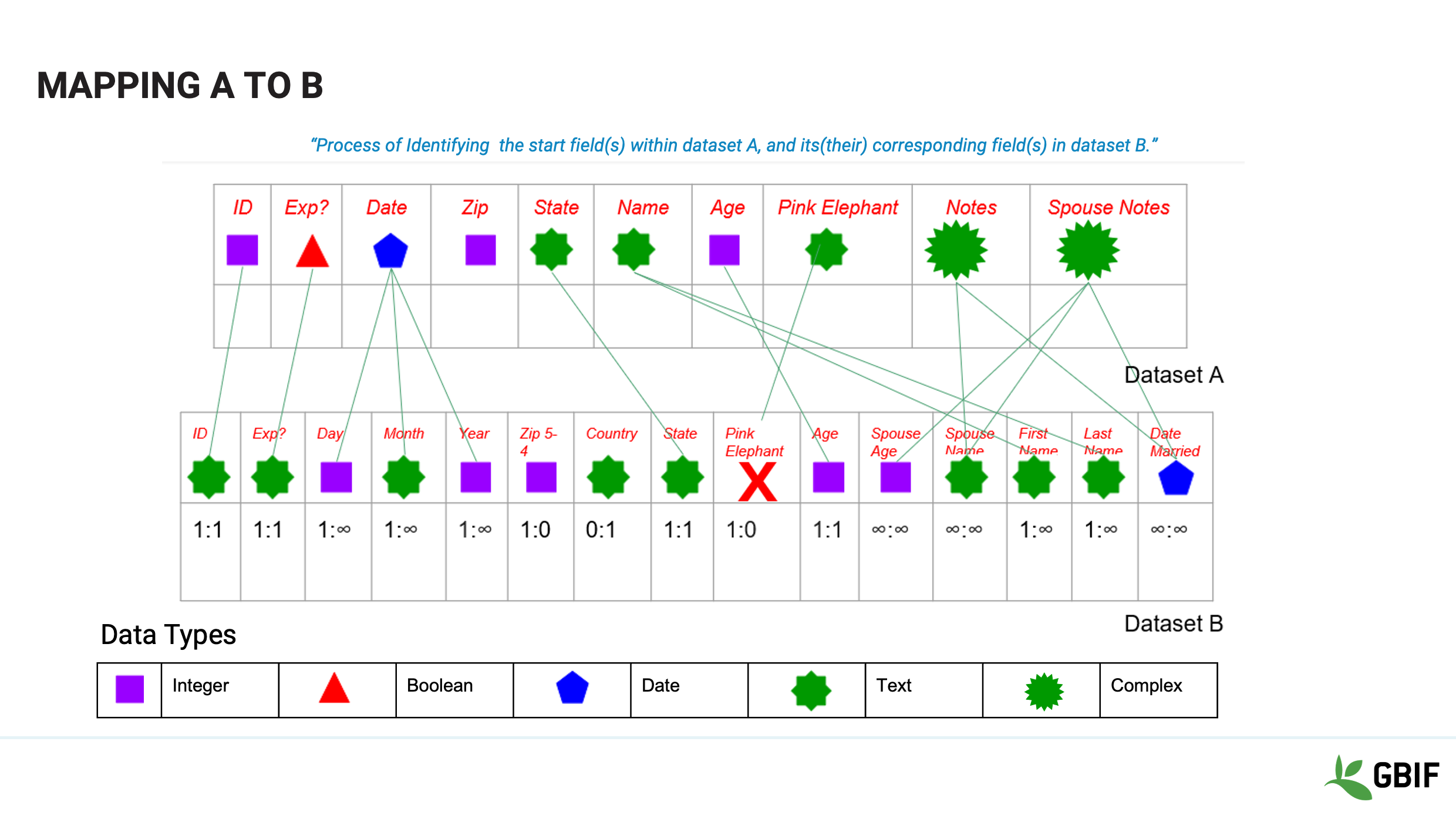
Slide 6 - Mapping A to B
We do that by describing the relationships.
For example Dataset A has an ID field and so does Dataset B. We can draw a line directly between the two. This is called a one to one match. Question: Can you see any other one to one matches? Answer: State, Exp?, Pink Elephant! Another type of relationship is is a one to many. In these cases there is a single field in dataset A that maps to 2 or more fields in Dataset B. Date is an example. You many also find cases where a more than one field in Dataset A contains data for more than one field in Dataset B. Notes fields are often guilty of this.

Slide 7 - Planning data moves - Data relationships
In fact there are six relationships:
-
Some fields will map one-to-one (1:1), meaning that the original column in dataset A exactly matches another one in dataset B
-
Some fields will map many-to-one (∞:1) , meaning that some columns in dataset A can be merged (or concatenated) to match a single one in dataset B
-
Some fields will map one-to-many (1:∞), meaning that one column in dataset A will have to be split into two or more fields in order to match the fields in dataset B
-
Some fields might not exist yet zero-to-one (0:1), meaning that some information are not present in dataset A and need to be added in a new column to match an existing field in dataset B
-
Some fields might not have a place to go one-to-zero (1:0), meaning that some information present in dataset A does not match any existing field on dataset B
-
Some fields will map many-to-many (∞ : ∞), meaning that information in dataset A is scattered in different fields, which do not match exactly existing ones in dataset B
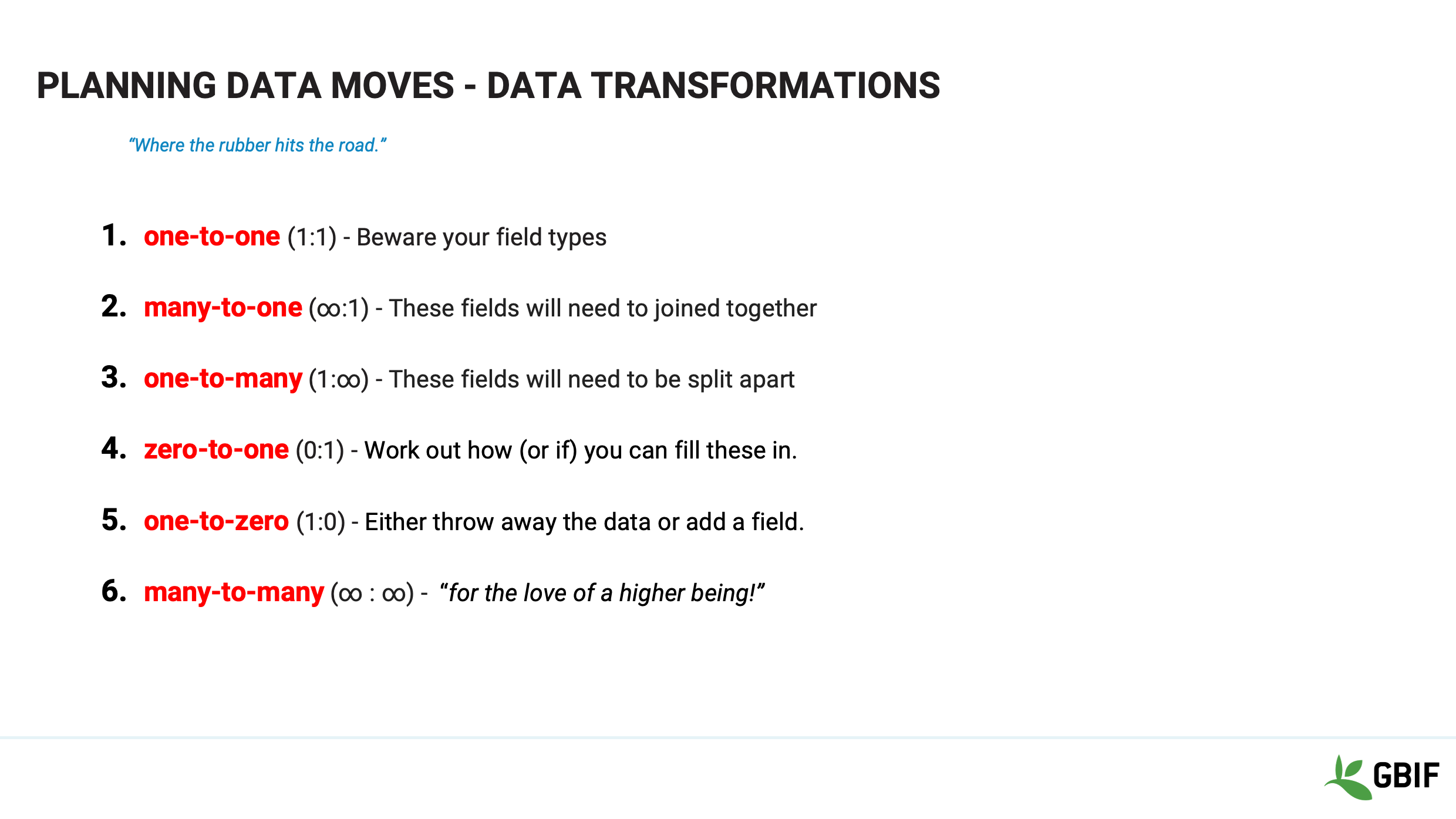
Slide 8 - Planning data moves - Transformations
Each of the relationship types has its own nuances as to how you are going to have to handle them.
-
one-to-one (1:1) - Beware your field types. If they are the not the same. You will need to do some manipulation.
-
many-to-one (∞:1) - These fields will need to joined together to go into the field.
-
one-to-many (1:∞) - These fields will need to be split apart and put in to different fields
-
zero-to-one (0:1) - Work out how (or if) you can even fill these in. Is the data mixed into a notes field? If so how do you get it out?
-
one-to-zero (1:0) - Either throw away the data or add a field.You might not even have a home in the other dataset. Do/Can you create a new field?
-
many-to-many (∞ : ∞) - “for the love of a higher being!” This usually means that your incoming data is very messy and will take time to clean before you can map it.
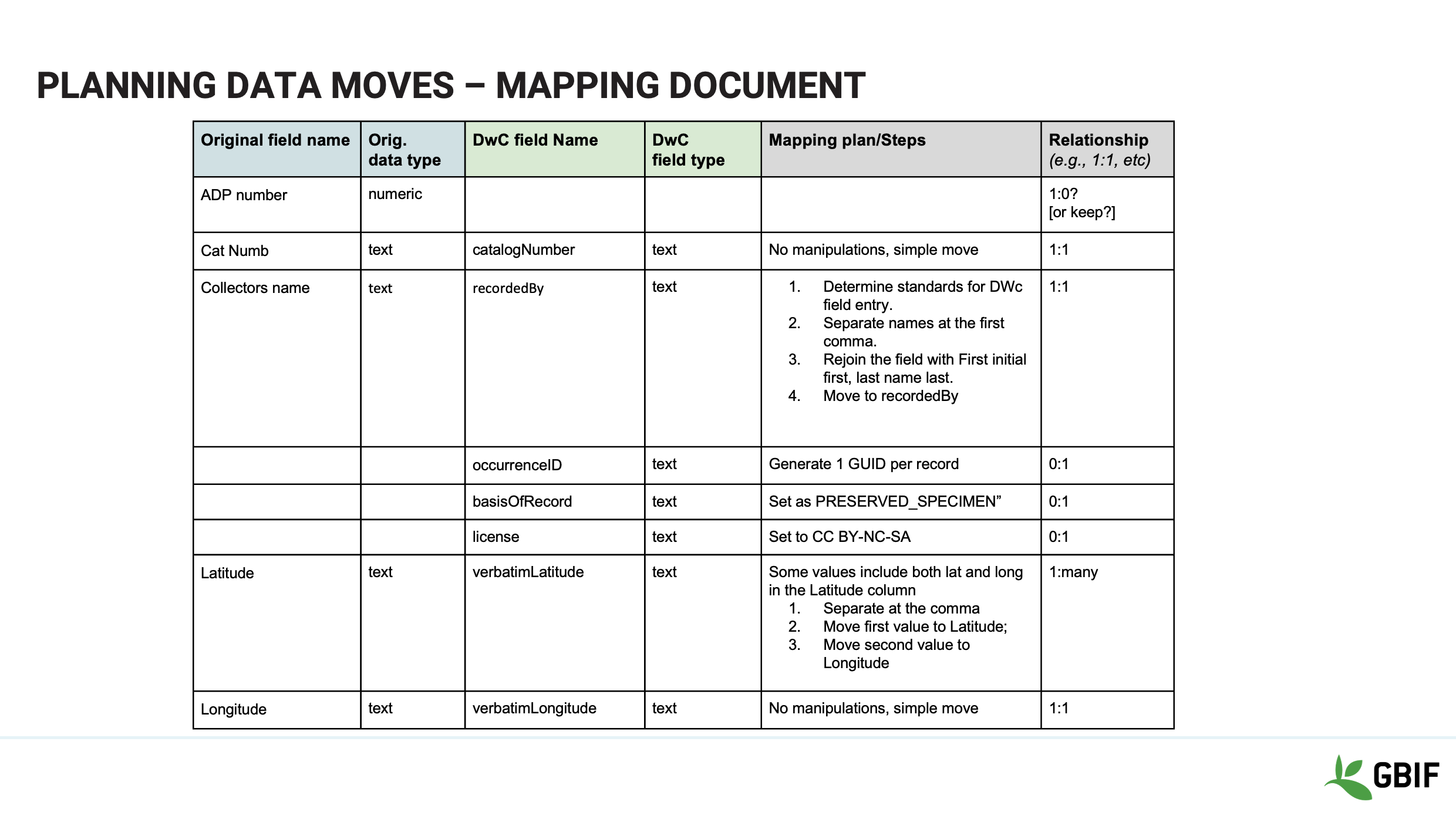
Slide 9 - Planning data moves - Mapping document
This is an example of what a mapping document looks like. Notice that not only do we document the relationships we also articulate (to the best of our knowledge) what should be done to the data.
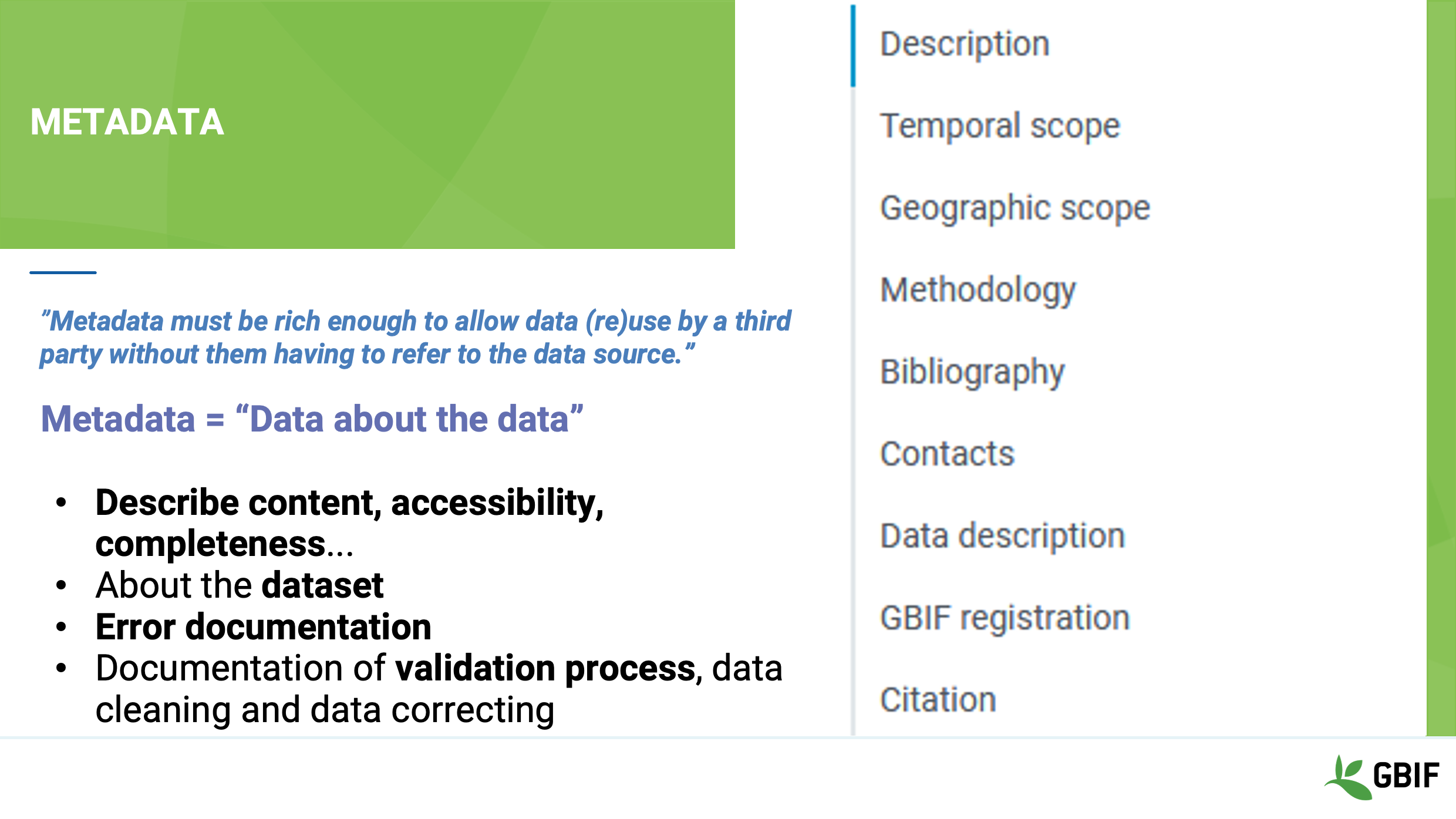
Slide 10 - Metadata
We’ve talked a lot about documenting the structures that hold your data but you must also document the information that gives context. This is called metadata and is data about your data! As we mention in the section on data quality your ”Metadata must be rich enough to allow data (re)use by a third party without them having to refer to the data source.”

Slide 11 - Metadata
We will discuss this in more detail in later sessions but as a quick guide good documentation should include:
-
A title – Which should be descriptive, memorable and if possible unique. Dates are good to include in a dataset name for example to allow you to track versions.
-
A narrative – Should describe the rationale for the creation of the dataset. It should include at least general information about spatial, temporal and taxonomic coverage and give the potential user a broad picture of uses that may be appropriate for the data without further transformation.
-
Source information – If you did not collect or measure the data yourself, where or who did you get if from?
-
Lineage – Does the dataset have a history? Have any of the fields been transformed in any way from the original?
-
Statement of accuracy – Using the concepts of accuracy, precision, errors and uncertainty that we discussed previously, are there any issues with the dataset that should be known to a user?
-
Dates and life expectancy – When will the dataset be available? How long is it valid for? When if ever will it be updated?
-
Field Definitions – Describing the format of fields and what kind of data each contains. Was any cleaning or transformation down to the original data? This is important for you to know if you are mapping it to a standard such as Darwin Core.
-
Collection methodology – How was the data collected? Where there protocols used which will affect its fitness for use?
-
Statement of completeness – What is missing from the data and why?
-
Conditions of use and constraints – Where and how can you use the data? For most portals and GBIF in particular data must use very open licensing, so understanding the requirements of data owners and their institutions is very important.
-
Custodianship/Contact information – This should be the institution responsible for the dataset as presented to you, as well as (if possible) the individual who created the dataset. There should also be a technical contact who is responsible for the publication of the dataset.

Diapositive 12 - Conclusion
This video is part of a series of presentations used in the GBIF Biodiversity Data Mobilization course. The biodiversity data mobilization curriculum was originally developed as part of the Biodiversity Information Development Programme funded by the European Union. This presentation was originally created by Sharon Grant and has been narrated by Sophie Pamerlon.