Data processing and quality
|
In this module, you will learn how to determine if data is fit for your purpose and how reviewing GBIF data quality issues and flags can help you process the data you are using for your research. |
Depending on your research question, you will need to decide if the available data/datasets are fit for your purpose.This will include evaluating the quality of the data.
|
In this video (12:26), you will review some of the principles for fitness for use and data quality. This video’s audience is directed towards the publishers of data, but many of the same principles apply to users of data. If you are unable to watch the embedded YouTube video, you can download it locally on the Files for download page. |
Determining fitness for use
For one person, data identified to the level of Genus may be sufficient to run predictive models of ecological niches. For a person studying a particular taxon, that same genus-level data will be much less useful than more detailed occurrences with subspecies information.
Based on the principles that Arthur Chapman discusses in the Principles of Data Quality (2005), you should reflect on some important questions about the data to help you decide if data is trustworthy or useful enough for your purpose:
-
How Accurate are the data? For example, are the identifications current and were they made by known experts?
-
How Timely are the data? When was the data made available? How often has it been updated?
-
How Complete or Comprehensive are the data? How well does the data cover a particular time, place, or domain?
-
How Consistent are the data? Are the data in each field always of the same type? Was the data collected using the same documented protocols?
-
How Relevant are the data? How similar is the dataset to others that have been used successfully for the same purpose?
-
How Detailed are the data? How much resolution is there in the data? At what scale can the data be used for mapping?
-
Is the data Easy to interpret? Is the dataset (metadata) documented in a clear and concise way?
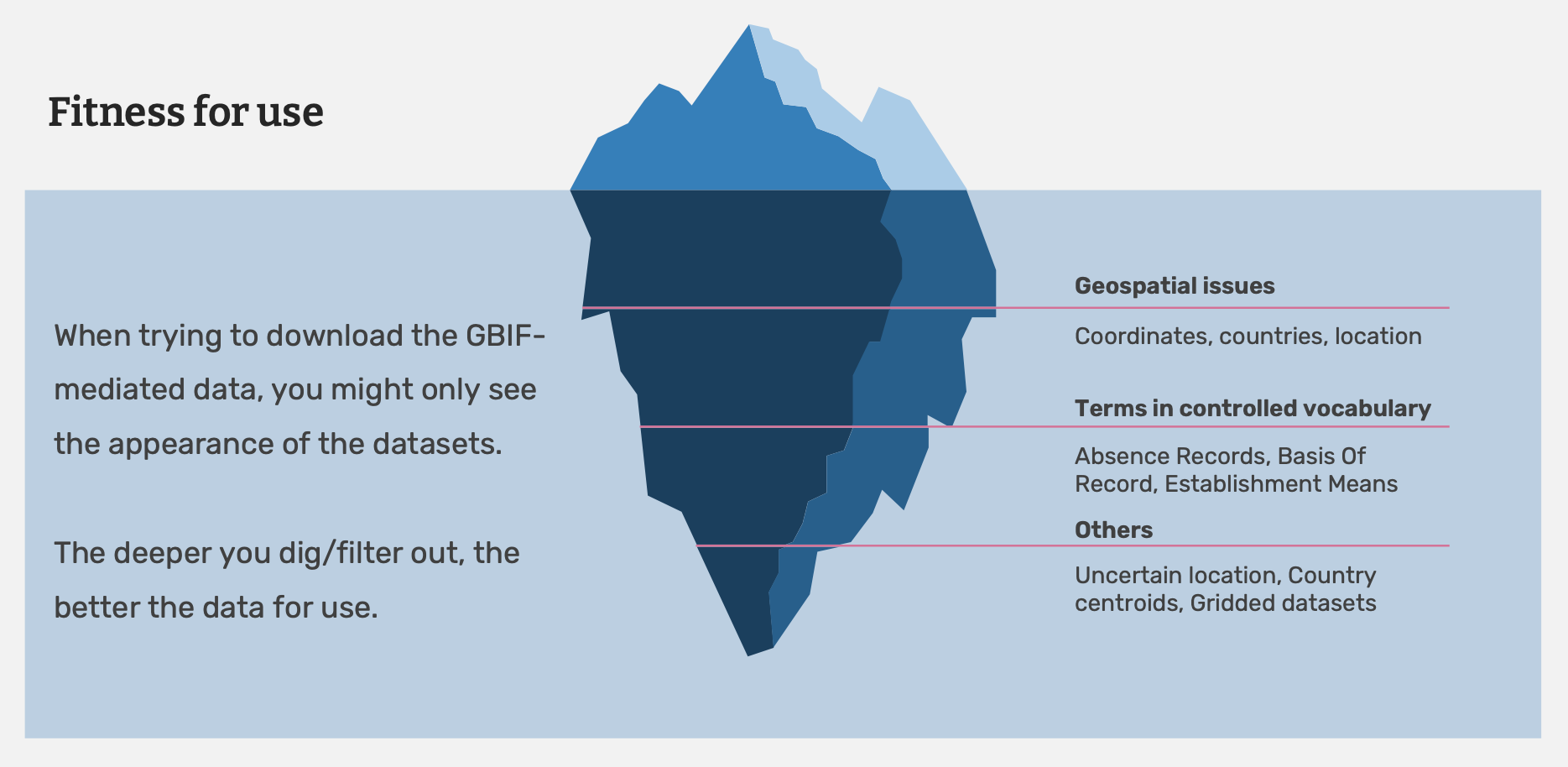
Evaluating data quality
If you have determined a dataset is fit for your purpose, you need to further examine the dataset and complete post-download processing of the data. GBIF downloads contain data from a range of sources and the data will likely vary in its measures of quality. Knowing the properties of the data you have will help you to understand the ways in which you can and cannot clean, validate and process the data.
| Below you will find a selected reading from Arthur Chapman’s guide “Principles of data quality”. Full document, references and translations can be found on GBIF.org. |