Calidad de (los) datos
| Este módulo ofrece una introducción a la calidad de los datos. |
Calidad de (los) datos
|
En este vídeo (12:26), repasará la terminología utilizada en este curso. Si no puede ver el vídeo incrustado, puede download hacerlo localmente. (MP4 - 56,4 MB) |
Transcripción de la presentación
Haga clic para ampliar

Página 1 - Fundamentos - Calidad de los datos
Los dos conceptos principales que exploraremos son Aptitud para el Uso (Fitness for Use) y Medidas de Calidad. Estas dos ideas sentarán las bases para conceptos y técnicas de calidad de datos más detallados en el futuro.
Foto: GBIF: https://www.gbif.org/occurrence/2550045989 Ictinaetus malayesnsis (Temminck, 1822) Titular de los derechos: cupag_kelley Licencia: http://creativeco…censes/by-nc/4.0/ Referencia: https://www.inatu…g/photos/58972976

Diapositiva 2 - Conceptos clave de calidad de datos
Los dos conceptos principales que exploraremos son Aptitud para el Uso (Fitness for Use) y Medidas de Calidad. Estas dos ideas sentarán las bases para conceptos y técnicas de calidad de datos más detallados en el futuro.
Foto: GBIF: https://www.gbif.org/occurrence/2550045989 Ictinaetus malayesnsis (Temminck, 1822) Titular de los derechos: cupag_kelley Licencia: http://creativeco…censes/by-nc/4.0/ Referencia: https://www.inatu…g/photos/58972976

Diapositiva 3 - Calidad de datos
Antes de comenzar, me gustaría tomarme un momento para explicar por qué la calidad de los datos es importante. La Limpieza está al lado de lo Divino, es una expresión que a veces usamos para describir la importancia de la calidad de los datos. En este caso, lo Divino puede entenderse como santidad, y cuando algo es santo, muchos lo consideran digno de nuestra confianza. Entonces, en el caso de la calidad de los datos, es más probable que confiemos y usemos los datos que se han limpiado y cuidado.
Foto: GBIF: https://www.gbif.org/occurrence/2611012759 Rhododendron kasangiae D.G. Long & Rushforth Titular de los derechos: Sangay Wangchuk Licencia: http://creativeco…censes/by-nc/4.0/ Referencia: https://www.inatu…g/photos/68350578

Diapositiva 4 - Calidad de datos
Volviendo al ámbito de la informática de la biodiversidad, la definición clásica de calidad de los datos fue acuñada en 2005 por Arthur Chapman. Escribió: "La calidad de los datos está relacionada con el uso y no puede evaluarse independientemente del usuario. En una base de datos, los datos no tienen calidad ni valor real (Dalcin 2004); sólo tienen un valor potencial que se materializa cuando alguien utiliza los datos para hacer algo útil. La calidad de la información está relacionada con su capacidad para satisfacer a sus clientes y satisfacer sus necesidades (English 1999)". Arthur Chapman" Y así, para nosotros, como responsables del mantenimiento de los datos, queremos que los datos que publicamos sean lo más satisfactorios posible para todos nuestros usuarios potenciales. Para ello, tratamos de ofrecer datos de la máxima calidad.
Foto: GBIF: https://www.gbif.org/occurrence/2634451942 Dendrochirus zebra (Cuvier, 1829) Titular de los derechos: Ryan Yue Wah Chan Licencia: http://creativeco…censes/by-nc/4.0/ Referencia: https://www.inatu…g/photos/76358738

Diapositiva 5 - Calidad de datos
Para ayudarle a llevar a cabo esta tarea, exploraremos la Adecuación para el Uso. También exploraremos las Medidas de Calidad, en concreto, la Corrección y la Coherencia. Se trata de conceptos importantes que deberá conocer y ser capaz de articular sobre sus propios datos o los datos que mantiene.
Foto: GBIF: https://www.gbif.org/occurrence/2238803261 Papilio paris Linnaeus, 1758 Titular de los derechos: CheongWeei Gan Licencia: http://creativeco…censes/by-nc/4.0/ Referencia: https://www.inatu…g/photos/35832506

Diapositiva 6 - Aptitud para el uso en el mundo real
Comencemos con un ejemplo de Aptitud para el Uso.Un zapatero crea un par de zuecos con el fin de cubrir los pies de una persona, como los que aparecen en la parte superior de esta imagen.
Referencia de la imagen: https://commons.wikimedia.org/wiki/File:Schuhmacher-1568.png
{kind=link}

Diapositiva 7 - Aptitud para el uso en el mundo real
Cuando el zapatero hizo estos zapatos, ¿sabía que esta chica los usaría para bailar? Tal vez.
Referencia de la imagen: https://www.publicdomainpictures.net/en/view-image.php?image=157723&picture=&jazyk=CN

Diapositiva 8 - Aptitud para el uso en el mundo real
¿Cree que el mismo zapatero sabía que un jardinero podría utilizar algún día los zapatos como macetas? Quizás no Imagen de referencia: Sharon Grant [https://www.flickr.com/photos/rondls_pics/4941594970/in/album-72157616943444786/]

Diapositiva 9 - Aptitud para el uso
A menudo oímos hablar de la idoneidad de los datos para su uso en las ciencias ecológicas, pero lo que debemos recordar es que los datos no son intrínsecamente buenos o malos. Más bien es el usuario de los datos quien les da su valor. Por ejemplo, para una persona, los datos identificados a nivel de género pueden ser suficientes para ejecutar modelos predictivos de nichos ecológicos. Para una persona que estudie un taxón concreto, esos mismos datos a nivel de género serán mucho menos útiles que ocurrencias más detalladas con información sobre subespecies.
Foto: GBIF: https://www.gbif.org/occurrence/1621797237 Calotes mystaceus Duméril & Bibron, 1837 Titular de los derechos: robbythai Licencia: http://creativeco…censes/by-nc/4.0/ Referencia: https://www.inatu…rg/photos/9949104
Diapositiva 10 - Aptitud para el uso
Entonces, ¿qué es la adecuación para el uso y cómo se relaciona con los datos? Cuando Chapman habla de la adecuación para el uso, dice que una vez que se ha creado y compartido un conjunto de datos, existen dos perspectivas principales sobre cómo se pueden utilizar esos datos: la perspectiva del creador y la perspectiva del usuario. Para ayudar a alguien a decidir si tus datos son fiables o lo suficientemente útiles, debes comprenderlos y saber cómo transmitirlos al usuario potencial. Estas son algunas de las preguntas importantes sobre los metadatos, o características de tus datos, que deberías poder responder y compartir con los demás: . ¿Qué tan Accesibles son sus datos?¿Con qué facilidad puede alguien acceder a sus datos?Las personas no pueden usar los datos si no pueden encontrarlos. . ¿Qué tan Exactos son sus datos?¿Se puede confiar en sus datos? Por ejemplo, ¿sus identificaciones están actualizadas y fueron realizadas por expertos conocidos? . ¿Cuán Oportunos son?¿Cuándo estarán disponibles los datos?¿Con qué frecuencia se actualizan? . ¿Qué tan Completos o Exhaustivos son los datos?¿Qué partes de su conjunto de datos están completamente documentadas?¿Cuán bien cubren los datos un momento, lugar o dominio en particular? . ¿Qué tan Consistentes son?¿Los datos de cada campo son siempre del mismo tipo?¿Se recopilaron los datos utilizando los mismos protocolos documentados? . ¿Qué tan Relevantes son?¿Qué tan similar es este conjunto de datos a otros que se han utilizado con éxito para el mismo propósito? . ¿Qué tan Detallados son los datos? ¿Cuánta resolución hay en tus datos? ¿En qué escala se pueden utilizar para el mapeo? . ¿Los datos son Fáciles de interpretar? ¿Está el conjunto de datos documentado de una manera clara y concisa? Si tus documentos están escritos a mano, ¿son legibles?
Foto: GBIF: https://www.gbif.org/occurrence/1932569869 Amphidromus goldbergi Thach & F. Huber, 2018 Titular de los derechos: Manual Caballer Licencia: http://creativeco…/licenses/by/4.0/ Identificador: https://mediaphoto.mnhn.fr/media/1546617441086USKcRv3tfQkB8mZo

Diapositiva 11 - Medidas de calidad
Mientras que la adecuación para el uso es subjetiva, las medidas de calidad de los datos lo son mucho menos. Chapman afirma que:
"Todos los datos contienen errores: ¡no hay escapatoria! Lo importante es saber cuál es el error, y saber si el error está dentro de los límites aceptables para el fin al que se destinan los datos. (Chapman 2005)"

Diapositiva 12 - Medidas de calidad
Podemos utilizar dos medidas de calidad, la corrección y la consistencia, para ayudarnos a documentar estos errores inherentes en los datos. La corrección, a veces llamada precisión, es "qué tan cerca está el valor registrado del valor real".
En este diagrama, la precisión es lo cerca que está un punto determinado del centro del blanco. La consistencia, a veces llamada precisión, es "la frecuencia con la que aciertas"
En este diagrama, la precisión es lo cerca que están los puntos entre sí, independientemente de lo cerca que estén del centro del objetivo. Son medidas de la capacidad del recopilador de datos para captar el verdadero valor investigado. Conocer estas propiedades de los datos te ayudará a comprender las formas en que puedes y no puedes limpiar, validar y procesar los datos.
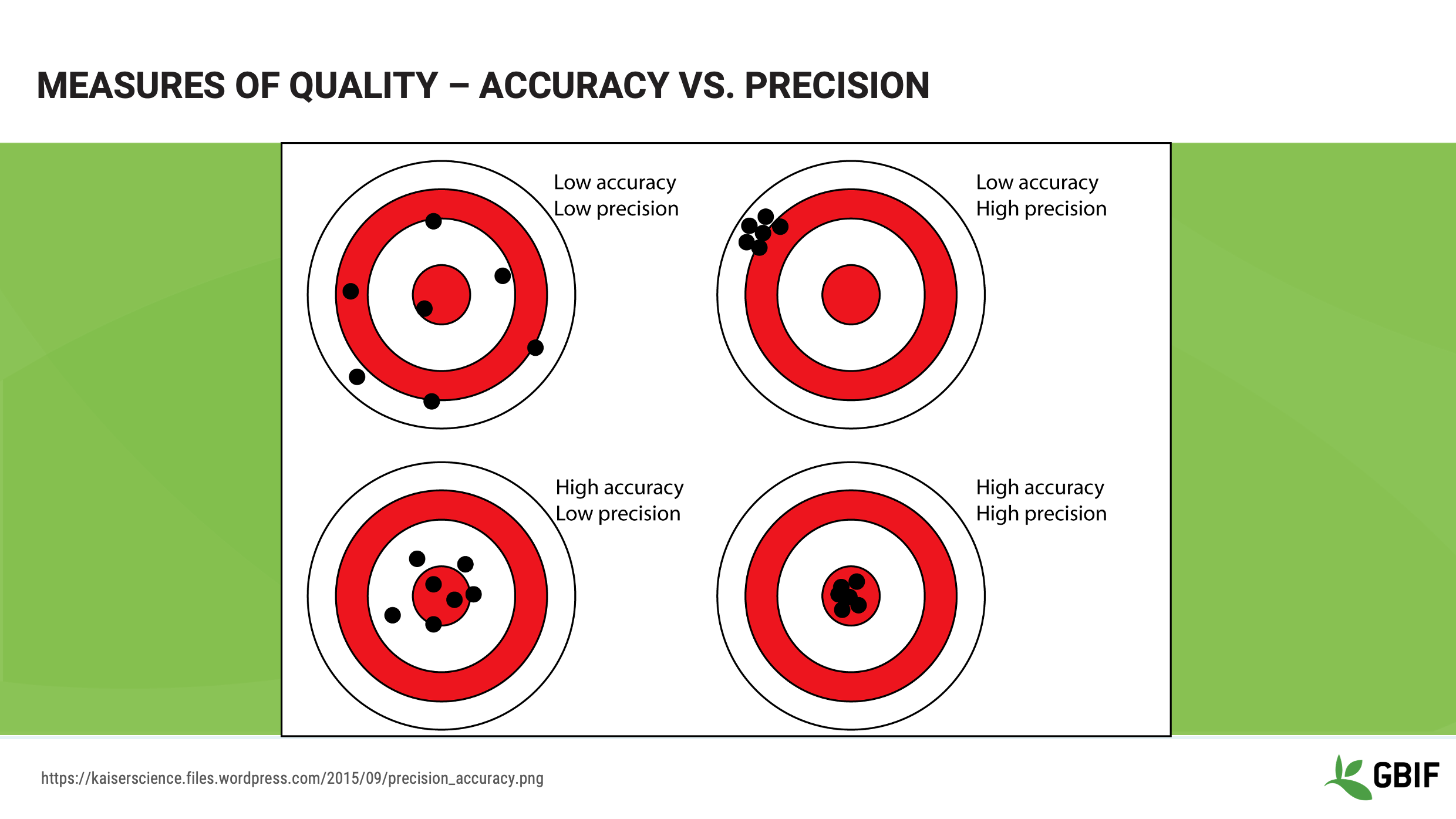
Diapositiva 13 - Medidas de calidad - Exactitud frente a precisión
Esta imagen proporciona un conjunto claro de ilustraciones de exactitud y precisión. Esta puede ser una buena imagen para tenerla con usted cuando tenga que explicar estos conceptos a otras personas.
Fuente de la imagen: https://kaiserscience.files.wordpress.com/2015/09/precision_accuracy.png
{kind=link}

-
Diapositiva 14 - Medidas de corrección de la calidad*
Veamos algunos ejemplos de corrección o precisión, y cómo puede ayudarnos a pensar en los aspectos prácticos de la limpieza de datos. Recuerda que la corrección se refiere a qué tan cerca estás del centro de un objetivo. Veamos un ejemplo

Diapositiva 15 - Medidas de corrección de la calidad - Ejemplo 1
Para este ejemplo, imaginemos que su conjunto de datos contiene registros de especímenes fósiles de aves del período Triásico Temprano. El nombre taxonómico de varios especímenes en su conjunto de datos es Thismia. ¿Sabe si Thismia es un taxón de aves antiguas? Referencia de la imagen: https://commons.wikimedia.org/wiki/File:Archaeopteryx_fossil.jpg
{kind=link}

Diapositiva 16 - Medidas de corrección de la calidad - Ejemplo 1
En este caso, ¡la respuesta es no! Thismia es una planta muy rara del estado de Illinois en los Estados Unidos. Por lo tanto, la exactitud del nombre taxonómico es baja. Quizás porque el técnico de entrada de datos no era paleontólogo. En consecuencia, es posible que todos los nombres en el conjunto de datos deban ser revisados y corregidos por un experto antes de que los datos puedan utilizarse. Foto: GBIF: (n/a) Thismia rodwayi Titular de los derechos: Tindo2 Licencia: http://creativeco…censes/by-nc/4.0/ Referencia(n/a): https://www.inaturalist.org/photos/596775?size=large

Diapositiva 17 - Medidas de corrección de la calidad - Ejemplo 2
Veamos otro ejemplo. En este caso, su conjunto de datos contiene especímenes recolectados en un lugar llamado Kalamazoo por un científico llamado Richard Spruce. Debemos preguntarnos:
¿Es 49007 el código postal correcto para Kalamazoo?
¿Coleccionó Richard Spruce en Michigan?

Diapositiva 18 - Medidas de corrección de la calidad - Ejemplo 2
En este caso, la respuesta es sí a nuestra primera pregunta, 49007 es un código postal para Kalamazoo, por lo que la precisión de la localidad es buena, pero ¿qué pasa con el coleccionista, Richard Spruce?
Referencias de imágenes: https://en.wikipedia.org/wiki/Richard_Spruce#/media/File:Spruce_Richard.jpg https://archive.org/details/notesofbotanisto21908spru
{kind=link}

Diapositiva 19 - Medidas de corrección de la calidad - Ejemplo 2
De hecho, existió un famoso botánico llamado Richard Spruce. Nació en 1817 y murió en 1893, pero realizó sus expediciones en la cuenca del Amazonas y la cordillera de los Andes en Sudamérica. Algo no cuadra del todo, así que necesitamos averiguar más sobre el recolector antes de poder estar seguros de la veracidad de estos datos. Referencias de imágenes: https://en.wikipedia.org/wiki/Richard_Spruce#/media/File:Spruce_Richard.jpg https://archive.org/details/notesofbotanisto21908spru

Diapositiva 20 - Medidas de consistencia de la calidad
Veamos ahora qué significa consistencia o precisión en los datos. La consistencia representa cuántas veces se obtiene la misma respuesta, independientemente de dónde se encuentre el centro del objetivo. Por ejemplo, su conjunto de datos contiene registros botánicos, incluyendo un campo o columna llamado "Nombre completo". Este campo contiene el nombre del recolector de especímenes. Como puede ver, hay cinco nombres diferentes, pero ¿cuántos recolectores únicos hay? ¿Puede determinarlo solo con mirar los nombres?

Diapositiva 21 - Medidas de consistencia de la calidad
A veces, si estás familiarizado con el conjunto de datos, es posible que sepas cuántos recolectores están representados con solo mirar los datos, pero si no conoces bien estos datos, es posible que necesites investigar un poco, hacer algunas preguntas o consultar las notas de campo originales. En este ejemplo, si adivinaste que estos cinco nombres representan a dos o tres coleccionistas únicos, estarías en lo cierto: En azul, Joseph Dalton Hooker y Hook.f. son la misma persona. Hook.f. es la abreviatura utilizada para Joseph Dalton Hooker (1817-1911). En verde, W. J. Hooker y Hook. son la misma persona. Hook. es la abreviatura de William Jackson Hooker (1785-1865). William era en realidad el padre de Joseph. Finalmente, en rojo, aparece “Hooker, J.”. Esta entrada podría ser un error o una errata de Joseph o William Hooker, o bien podría tratarse de una tercera persona con un nombre similar. Por lo tanto, se necesitaría más investigación para aclarar estos datos. Referencia: http://www.ipni.org/ipni/advAuthorSearch.do;jsessionid=087C235AF7757EF21CA33FF5325C94C7?find_forename=&find_surname=Hooker&find_abbreviation=&find_isoCountry=&output_format=normal&back_page=authorsearch&query_type=by_query

Diapositiva 22 - Limpieza de datos
Acabamos de analizar varios ejemplos sencillos de dos medidas de calidad de datos. Estos ejemplos deberían proporcionarle una comprensión básica de cómo identificar las inexactitudes e imprecisiones en los datos. La forma en que documentamos y corregimos estos problemas o errores es un proceso que llamamos limpieza de datos. Más específicamente: La limpieza de datos es el proceso de corregir o eliminar datos erróneos causados por contradicciones, discrepancias, errores de introducción de datos, bits faltantes, entre otros. También incluye la validación de los cambios realizados y puede requerir la normalización. La limpieza de nuestros datos, o la falta de ella, afectará a la percepción que tengan los usuarios sobre la adecuación de sus datos para su uso. No es necesario que usted mismo realice toda la limpieza de datos; de hecho, una idea errónea común es que todos los errores DEBEN corregirse antes de poder compartir sus datos. Lo cierto es que solo puedes limpiar la cantidad de datos que te permitan tu tiempo, conocimiento y recursos. Por lo tanto, es fundamental documentar lo que sabes y lo que desconoces sobre tus datos para que, cuando los compartas, los usuarios conozcan su nivel de calidad.

Diapositiva 23 - Conclusión
Este vídeo forma parte de una serie de presentaciones utilizadas en el curso de Movilización de Datos de Biodiversidad del GBIF. El programa de estudios sobre movilización de datos de biodiversidad se desarrolló originalmente como parte del Programa de Desarrollo de Información sobre Biodiversidad, financiado por la Unión Europea.
Esta presentación fue creada originalmente por Sharon Grant, con contribuciones adicionales de Dag Endresen y David Bloom. La narración estuvo a cargo de David Bloom.
Principios de calidad de datos
| A continuación encontrará una selección de lectura de la guía de Arthur Chapman "Principios de la calidad de datos". Full document, Se pueden encontrar referencias y traducciones en GBIF.org. |
Antes de que pueda tener lugar una discusión detallada sobre calidad de los datos y su aplicación a datos de presencia de especies, hay una serie de conceptos que necesitan ser definidos y descritos. Estos incluyen el término calidad de los datos en sí, los términos exactitud y precisión que a menudo son mal aplicados, y lo que entendemos por datos primarios de especies y datos de presencia de especies.
Datos de presencia de especies
Los datos de presencia de especies se utilizan aquí para incluir datos de etiquetas de especímenes adjuntas a especímenes o lotes conservados en museos y herbarios, datos de observación y datos de encuestas medioambientales. En general, los datos son lo que denominamos «basados en puntos», aunque también se incluyen datos lineales (datos de transectos de encuestas medioambientales, recolecciones a lo largo de un río), poligonales (observaciones dentro de un área definida, como un parque nacional) y cuadriculados (observaciones o registros de encuestas de una cuadrícula regular). En general, se trata de datos georreferenciados, es decir, registros con referencias geográficas que los vinculan a un lugar concreto en el espacio -ya sea con una coordenada geo referenciada (por ejemplo, latitud y longitud, UTM) o no (descripción textual de una localidad, altitud, profundidad)- y tiempo (fecha, hora del día).
En general, los datos también están vinculados a un nombre taxonómico, pero también pueden incluirse colecciones no identificadas. En ocasiones, el término se ha utilizado indistintamente con el de «datos primarios de especies».
Datos de especies primarias
"Datos primarios de especies" se utiliza para describir los datos brutos de recogida y los datos sin atributos espaciales. Incluye datos taxonómicos y de nomenclatura sin atributos espaciales, como nombres, taxones y conceptos taxonómicos sin referencias geográficas asociadas.
Exactitud y Precisión
La exactitud e la precisión están regularmente confundidas y generalmente no se entienden las diferencias.
Exactitud se refiere a la cercanía de los valores medidos, de las observaciones o de las estimaciones al valor real o verdadero (o al valor que se acepta como verdadero - por ejemplo, las coordinadas de un punto de control).
Precisión (o resolución) puede ser dividida en dos tipos principales. Precisión estadística es la cercanía con la cual observaciones repetidas se conforman a ellas mismas. No tienen nada que ver con su relación con el valor real, y pueden tener una gran precisión, pero poca exactitud. Precisión numeral es el número de dígitos con que se registra una observación y se ha hecho mucho más evidente con la llegada de los ordenadores. Por ejemplo, una base de datos puede mostrar un registro decimal de latitud/ longitud con 10 decimales, es decir, unos 0,01 mm, cuando en realidad el registro tiene una resolución no superior a 10-100 m (3-4 decimales). Eso suele dar una falsa impresión tanto de la resolución como de la precisión.
Los siguientes términos- exactitud y precisión - pueden ser aplicados también a los datos no espaciales al igual que a los datos espaciales. Por ejemplo, una colección puede tener una identificación a un nivel de subespecie (es decir, tener una alta precisión) pero ser el taxón equivocado (es decir, tener una baja precisión) o estar identificada sólo a nivel de Familia (alta exactitud, pero baja precisión)…
Calidad de datos
La calidad de los datos es multidimensional e implica su gestión, modelización y análisis, control y garantía de calidad, almacenamiento y presentación. Como afirman de forma independiente Chrisman (1991) y Strong et al. (1997), la calidad de los datos está relacionada con el uso y no puede evaluarse independientemente del usuario. En una base de datos, los datos no tienen calidad ni valor real (Dalcin 2004); sólo tienen un valor potencial que sólo se materializa cuando alguien utiliza los datos para hacer algo útil. La calidad de la información está relacionada con su capacidad para satisfacer a sus clientes y cubrir sus necesidades (English 1999).
Redman (2001), sugirió que para que los datos sean aptos para su uso deben ser accesibles, precisos, oportunos, completos, coherentes con otras fuentes, pertinentes, exhaustivos, ofrecer un nivel de detalle adecuado, ser fáciles de leer y fáciles de interpretar.
Una cuestión que el responsable de la base de datos puede tener que plantearse es qué puede ser necesario hacer con la base de datos para aumentar su usabilidad para un público más amplio (es decir, aumentar su uso potencial o relevancia) y, por lo tanto, hacerla apta para una gama más amplia de propósitos. Habrá un equilibrio entre la mayor facilidad de uso y el esfuerzo necesario para añadir funcionalidad y facilidad de uso adicionales. Para ello puede ser necesario atomizar los campos de datos, añadir información de georreferenciación, etc.
Garantía de calidad/Control de calidad
La diferencia entre control de calidad y garantía de calidad no siempre está clara. Taulbee (1996) distingue entre control de calidad y garantía de calidad y subraya que no puede existir uno sin el otro si se quieren alcanzar los objetivos de calidad. Define el control de calidad como un juicio sobre la calidad basado en normas, procesos y procedimientos internos establecidos para controlar y supervisar la calidad; y la garantía de calidad como un juicio sobre la calidad basado en normas externas al proceso y consiste en la revisión de las actividades y los procesos de control de calidad para garantizar que los productos finales cumplen unas normas de calidad predeterminadas. Habrá un equilibrio entre la mayor facilidad de uso y el esfuerzo necesario para añadir funcionalidad y facilidad de uso adicionales. Para ello puede ser necesario atomizar los campos de datos, añadir información de georreferenciación, etc.
En un enfoque más orientado a la empresa, Redman (2001) define la Garantía de Calidad como «aquellas actividades destinadas a producir productos de información sin defectos para satisfacer las necesidades más importantes de los clientes más importantes, al menor coste posible».
No está claro cómo deben aplicarse estos términos en la práctica, y en la mayoría de los casos parecen utilizarse como sinónimos para describir la práctica general de la gestión de la calidad de los datos.
Incertidumbre
La incertidumbre puede considerarse como una «medida de lo incompleto del conocimiento o la información que se tiene sobre una cantidad desconocida cuyo valor real podría establecerse si se dispusiera de un dispositivo de medición perfecto» (Cullen y Frey 1999). La incertidumbre es una propiedad de la comprensión de los datos por parte del observador, y tiene más que ver con el observador que con los datos en sí. Siempre hay incertidumbre en los datos; lo difícil es registrar, comprender y visualizar esa incertidumbre para que otros también puedan entenderla. La incertidumbre es un término clave para entender el riesgo y su evaluación.
Error
El error engloba tanto la imprecisión de los datos como su inexactitud. Hay muchos factores que contribuyen al error. En general, se considera que el error puede ser aleatorio o sistemático. El error aleatorio suele referirse a la desviación del estado real de forma aleatoria. El error sistemático o sesgo surge de un desplazamiento uniforme de los valores y a veces se describe como de «precisión relativa» en el mundo cartográfico (Chrisman 1991). A la hora de determinar la «idoneidad para el uso», el error sistemático puede ser aceptable para algunas aplicaciones e inadecuado para otras.
Un ejemplo puede ser el uso de un datum geodésico diferente1, que, si se utiliza en todo el análisis, puede no causar mayores problemas. Sin embargo, surgirán problemas cuando un análisis utilice datos procedentes de diferentes fuentes y con diferentes sesgos, por ejemplo, fuentes de datos que utilicen diferentes datums geodésicos, o cuando las identificaciones se hayan realizado utilizando una versión anterior de un código nomenclatural.
«Dado que el error es ineludible, debe reconocerse como una dimensión fundamental de los datos» (Chrisman 1991). Sólo cuando se incluye el error en una representación de los datos es posible responder a preguntas sobre las limitaciones de los datos, e incluso sobre las limitaciones de los conocimientos actuales. Los errores conocidos en las tres dimensiones de espacio, atributo y tiempo deben medirse, calcularse, registrarse y documentarse.
Validación y Limpieza
La validación es un proceso utilizado para determinar si los datos son inexactos, incompletos o poco razonables. El proceso puede incluir comprobaciones de formato, comprobaciones de integridad, comprobaciones de razonabilidad, comprobaciones de límites, revisión de los datos para identificar valores atípicos (geográficos, estadísticos, temporales o medioambientales) u otros errores, y evaluación de los datos por expertos en la materia (por ejemplo, especialistas taxonómicos). Estos procesos suelen dar lugar a la señalización, documentación y posterior comprobación de los registros sospechosos. Los controles de validación también pueden implicar la comprobación del cumplimiento de las normas, reglas y convenciones aplicables. Una etapa clave en la validación y depuración de datos es identificar las causas fundamentales de los errores detectados y centrarse en evitar que vuelvan a producirse (Redman 2001).
La limpieza de datos se refiere al proceso de «corregir» los errores en los datos que se han identificado durante el proceso de validación. El término es sinónimo de «limpieza de datos», aunque algunos utilizan la limpieza de datos para englobar tanto la validación como la limpieza de datos. En el proceso de limpieza de datos es importante que los datos no se pierdan inadvertidamente y que los cambios en la información existente se lleven a cabo con mucho cuidado. A menudo es mejor conservar los datos antiguos (originales) y los nuevos (corregidos) uno al lado del otro en la base de datos, de modo que si se cometen errores en el proceso de limpieza, se pueda recuperar la información original.