Datos mediados por GBIF
| En este módulo, aprenderá sobre los datos primarios de biodiversidad y los principios que GBIF sigue en relación con ellos. Descubrirá cómo GBIF facilita el acceso a estos datos, los tipos de conjuntos de datos aceptados y cómo utiliza la estructura taxonómica para proporcionar información taxonómica. También tendrá la oportunidad de revisar las diversas métricas disponibles para los datos en el portal. |
Datos primarios sobre biodiversidad
|
En este vídeo (12:03), Cecilie Svenningsen, Administradora de Productos de Datos de GBIF, explica cómo se comparten los datos con GBIF y cómo se pueden utilizar, además de describir las normas de biodiversidad y los tipos de conjuntos de datos de GBIF. Si no puede ver el vídeo incrustado de Vimeo, puede descargarlo localmente (MP4 - 73,1 MB). |
Presentation transcript
Haga clic para ampliar

Diapositiva 1 - ¿Cómo se comparten los datos en GBIF.org?
Una cosa a tener en cuenta es que los publicadores de datos en GBIF poseen y mantienen sus datos, y luego los comparten con GBIF.
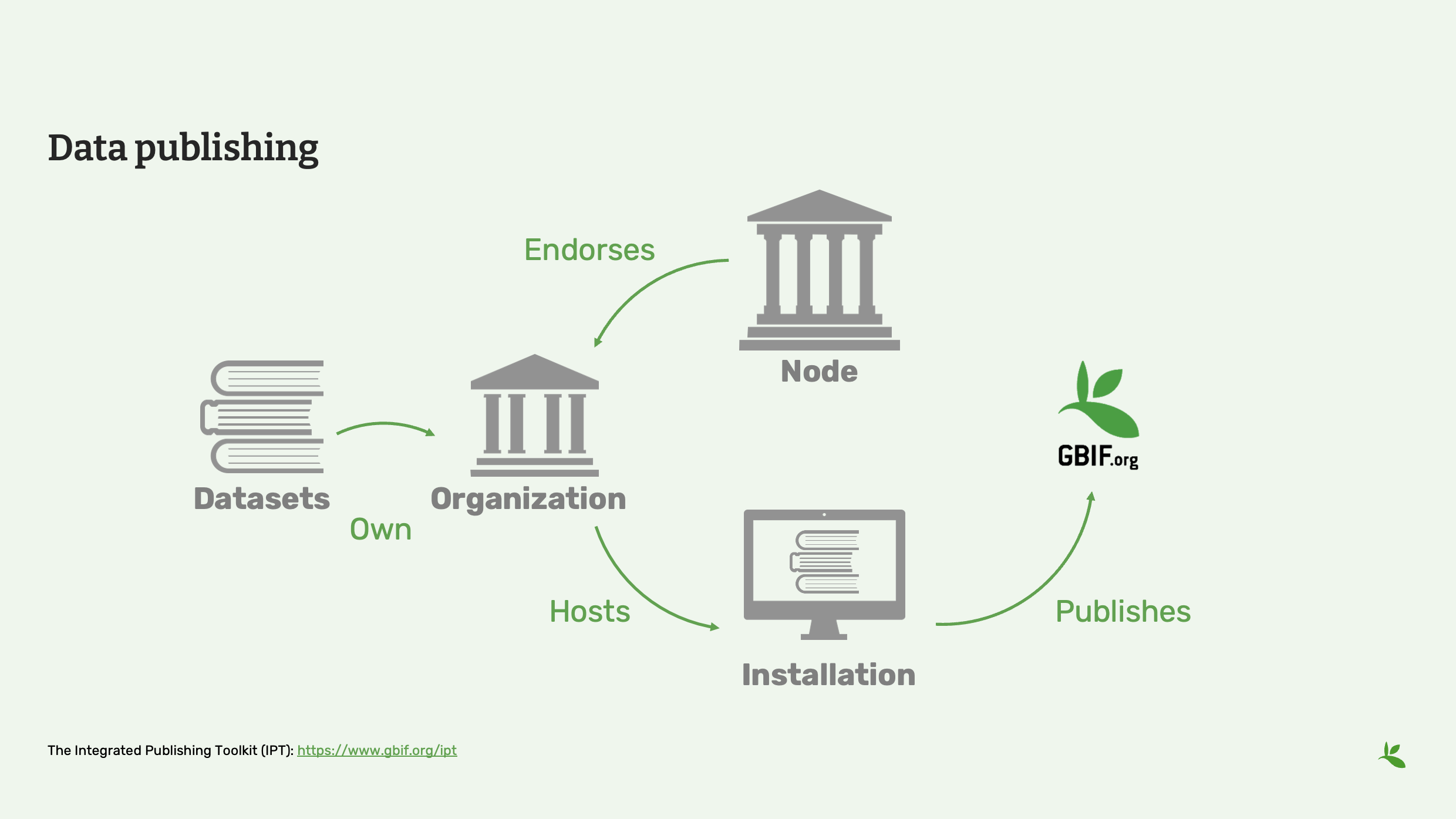
Diapositiva 2 - Publicación de datos
El funcionamiento es el siguiente: contamos con un conjunto de datos que pertenece a una organización. Dicha organización debe tener el endoso por un nodo de GBIF, que puede ser un nodo nacional o cualquier otro nodo participante, para poder compartir datos con GBIF.
Esos datos deben alojarse en algún lugar de una instalación, por ejemplo, en el Integrated Publishing Toolkit (IPT) integrado que proporciona GBIF.
Así que los conjuntos de datos se alojan allí, y luego pueden publicarse en GBIF y compartirse con usted.

Diapositiva 3 - Los datos compartidos en GBIF son heterogéneos
Otro aspecto a tener en cuenta es que los datos en GBIF son bastante heterogéneos. Estas organizaciones que comparten datos con GBIF provienen de fuentes muy diversas, y se trata de un proceso respaldado por la comunidad, como ya mencioné, donde los nodos avalan a las organizaciones que publican los datos, y estas pueden ser desde universidades y museos hasta agencias gubernamentales, etcétera.
Por lo tanto, lo que comparten puede provenir de proyectos de investigación o esfuerzos de monitoreo, datos de ciencia ciudadana o recopilaciones.
También hay que tener en cuenta que esos datos no están disponibles en tiempo real en GBIF.
Puedes tener datos que formen parte de un esfuerzo conjunto de una colección, una colección de museo que podría estar digitalizando sus datos de hace 50 o 70 años, y al día siguiente, están disponibles en GBIF.
Diapositiva 4 - Acceso y descarga de datos
Para que vea cómo se ve una búsqueda agregada para Ud. como usuario, si entra y quiere ver una especie, en este caso, la mariposa punta naranja. Si, como la mayoría de nuestros usuarios, entra a nuestro portal y busca la especie, lo primero que encontrará es la página de la especie.
Eso te mostrará una descripción general de la especie y la distribución de su presencia en GBIF. Sin embargo, normalmente tendría que ir a la página de registro de presencia, donde aplicaría filtros adicionales.
En este caso, me refiero a que solo quiero registros del período comprendido entre 2020 y 2022, creo. Y también es imprescindible que sean del continente europeo.
Así que he acotado mi búsqueda y hago clic en descargar, donde tengo que elegir diferentes opciones. En este caso, elijo la opción sencilla.
Pero también puede ver otra información, como problemas conocidos con los datos, que quizás debería consultar si quiere aplicar filtros adicionales a su descarga, si no quiere que se incluyan esos datos.
En su perfil de usuario de GBIF, podrá ver todas las descargas que haya realizado.
En este caso, les muestro el que acabo de crear, los filtros. Pero también verán que 927 conjuntos de datos contribuyeron a esta búsqueda agregada.
Así pues, diversas fuentes aportaron datos. Esto es importante porque influye en el contenido de los datos que descargue.
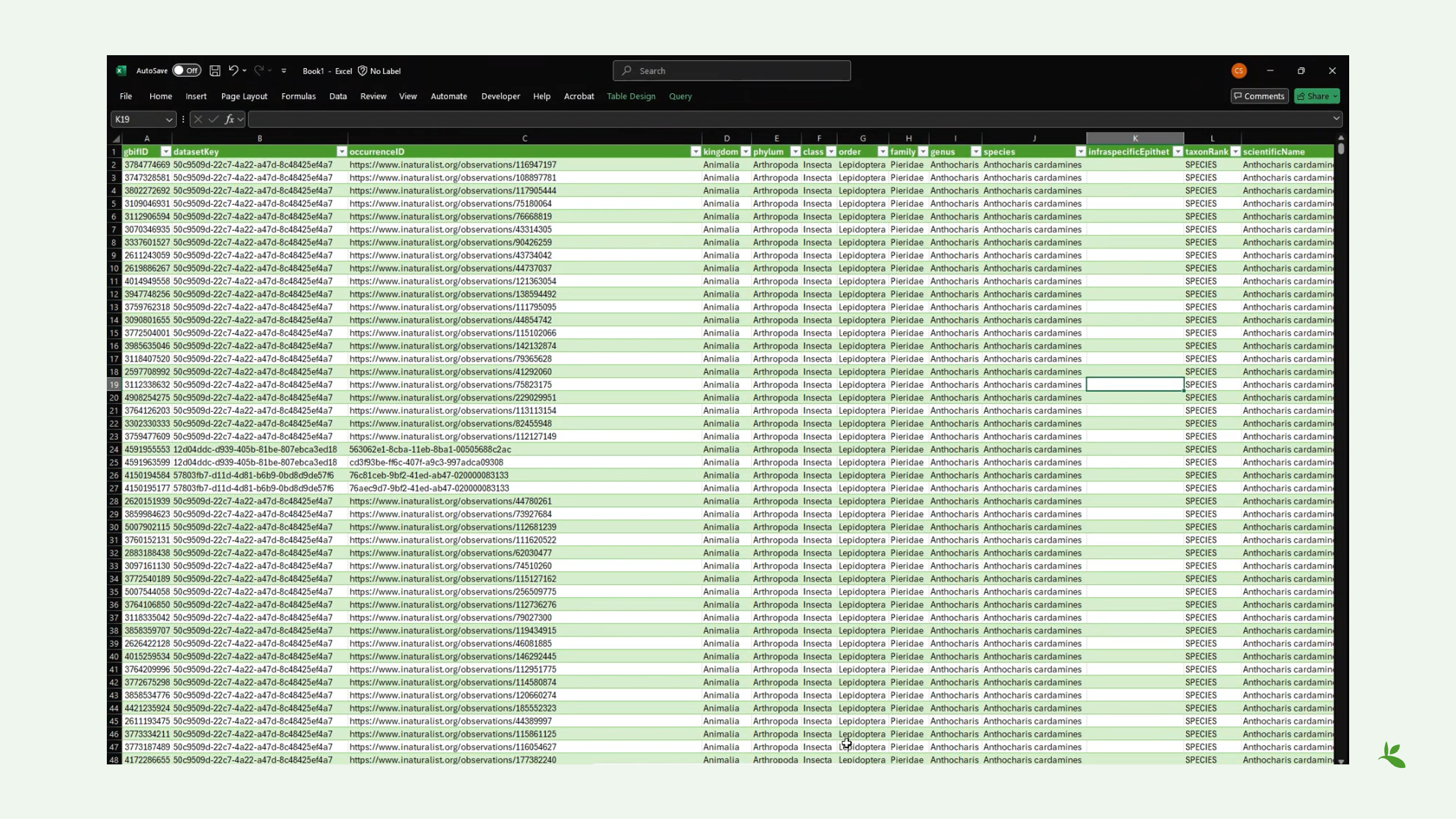
Diapositiva 5 - Revisión de una descarga
Este es un ejemplo de la descarga simple que acabo de crear, donde hay menos campos y columnas disponibles. Pero si descarga el archivo completo de Darwin Core, tendrá muchos campos para buscar. Sin embargo, notará que algunos de estos campos parecen estar vacíos, sin ningún valor. Pero como puede ver, tal como se lo muestro ahora, sí hay información de localidad compartida por algunos publicadores.
Esto significa que algunos publicadores podrían estar compartiendo datos, mientras que otros no. Y eso puede ser relevante para su análisis.
Por ejemplo, el recuento de individuos (individualCount), que puede dar una idea de la abundancia de la especie, puede que no lo incluyan algunos publicadores, pero sí otros.
Y como ya mencioné, si tiene la descarga completa del archivo Darwin Core, que tiene muchas más columnas, verá un conjunto de datos mucho más fragmentado, lo cual es importante para el procesamiento posterior de sus datos.

Diapositiva 6 - ¿En qué medida hay contenido en los campos que descarga?
Si analizamos con más detalle el contenido que puede esperar de los datos que descargue en GBIF, le daré algunas ideas generales sobre algunos de los campos que podría descargar.
El ID de GBIF, que aplicamos al registro compartido con GBIF, siempre es del 100 %. Siempre se obtienen todos los ID de GBIF para sus datos. Sin embargo, si busca información sobre el hábitat, al revisar todos los registros de biodiversidad en GBIF, solo alrededor del 7 % contiene datos en ese campo.
Los recuentos individuales (individualCount) son bastante altos, al igual que los estados y provincias (statePrvince), pero tenga en cuenta que esto se debe a las aves. El mayor grupo de datos que tenemos en GBIF proviene de las aves, por lo que realmente aumentan la cantidad de datos disponibles. Por lo tanto, puede variar bastante según el grupo.
Por lo tanto, si busca insectos, es posible que descubra que el porcentaje de valores que están realmente cubiertos es bastante bajo.
Con nombre científico (scientificName), está bastante bien.
En cuanto a la profundidad, si lo que se busca son datos sobre sucesos marinos, muy pocos publicadores comparten esa información.
Lo mismo ocurre con la elevación, y la etapa de la vida (lifeStage) es sólo del 9%.
La mayoría de nuestros publicadores proporcionan algún tipo de dato temporal, pero podría ser sólo en forma de año.
Así que tenlo en cuenta cuando uses tus datos.

Diapositiva 7 - Estándares de datos
Así que voy a hablar un poco sobre los estándares de datos que están detrás de lo que ves en GBIF. Como habrán notado, las columnas tienen nombres bastante específicos. Estos nombres y campos están definidos por estándares de datos, que son mantenidos por una comunidad global de biodiversidad.

Diapositiva 8 - Archivos de Darwin Core (DwC-A)
Así que la mayoría de los datos compartidos con GBIF suelen estar dentro de un archivo Darwin Core, como también he mencionado antes. Y los publicadores que comparten datos con GBIF tienen que mapear sus datos a este estándar Darwin Core.
Lo mantiene el Biodiversity Information Standards, también llamado TDWG.
Y esos estándares de datos definen el nombre del campo, como he mencionado, y a veces también definen el contenido del valor que podría ser como un vocabulario controlado o algún tipo de valor normalizado que la gente debe utilizar cuando comparten sus datos.
Digamos que usted es un publicador, que es completamente nuevo en los estándares de datos y en la publicación en GBIF. Puede que tenga una hoja de cálculo con un nombre, un recuento de cuántas especies ha visto y algunas notas generales sobre lo que ha encontrado.
Esos campos tienen que llamarse nombre científico (scientificName) para el nombre, por ejemplo, recuento individual (individualCount) para los recuentos, y para las notas, puede que quiera ponerlas en observaciones de registro (occurrenceRemarks) o en observaciones de evento (eventRemarks).
La cuestión es que tiene campos específicos para capturar información específica.

Diapositiva 9 - Campos disponibles
Ahora, los campos disponibles para compartir en GBIF, dependen de la clase de conjunto de datos.
Como he mencionado, tiene registros biológicos (occurrences). Esos registros biológicos son un tipo de clase de conjunto de datos en GBIF.
El más sencillo es el conjunto de metadatos, que en realidad no contiene ningún dato. Es sólo una descripción del conjunto de datos. Podría ser la descripción de una colección o la descripción de un estudio de campo, pero en el que aún no se han podido digitalizar los datos.
También tenemos los conjuntos de datos de listados taxonómicos (checklist), que son una lista de nombres de taxones. Podría incluirse más información, pero en general se trata de compartir los nombres científicos de una zona determinada o dentro de un ámbito específico diferente.
Y luego están los registros biológicos (occurrences), que ya he mencionado antes, que son las pruebas de la presencia de una especie o un taxón en una fecha y un lugar determinados.
Ahora, el último tipo de clase de conjunto de datos que tenemos son los eventos de muestreo (event), que tienen un poco más de información porque normalmente la gente tiene que compartir el esfuerzo de muestreo y el protocolo, y puede permitir a los usuarios evaluar la composición de la comunidad y la abundancia de especies.
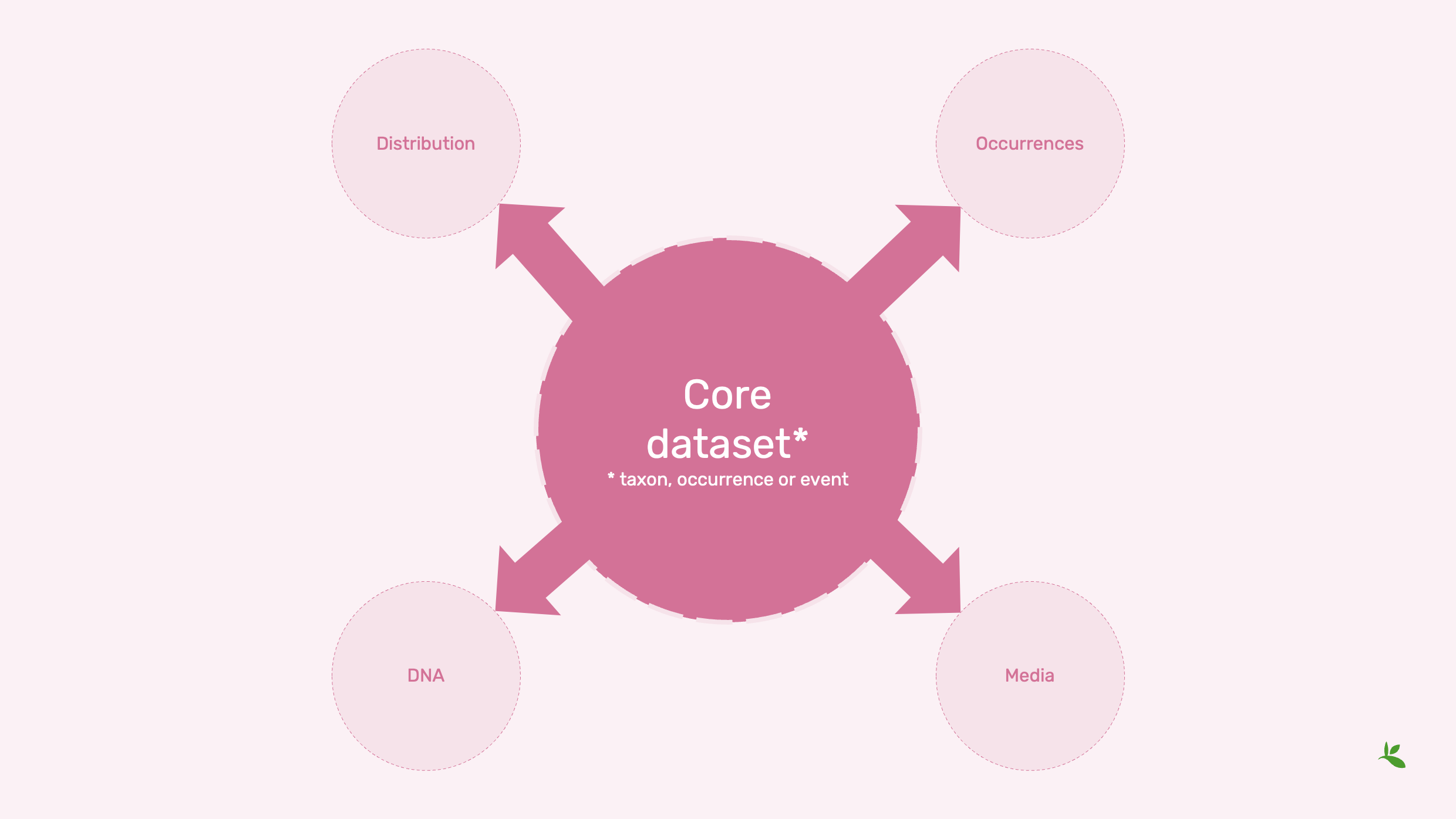
Diapositiva 10 - Núcleos del conjunto de datos
Ahora bien, esas clases de conjuntos de datos son tablas principales. Por lo tanto, si tiene una tabla de conjunto de datos que sea una tabla de taxones, registros biológicos, o eventos, esas tablas tienen un conjunto específico de campos que puede compartir. Pero es posible que desee compartir aún más información.
Por ejemplo, si tiene un conjunto de datos de eventos, puede que desee compartir registros biológicos individuales.
Si realizó un BioBlitz desde el comienzo del sábado hasta el final del mismo, pero dentro de ese lapso, encontró esa mariposa o ese escarabajo en un momento específico.
Es un registro biológico dentro del evento del BioBlitz.
O tal vez tengas material multimedia asociado. Tomaste fotos de los diferentes insectos que encontraste durante ese tiempo, o incluso tomaste muestras de ADN, y luego realizaste identificaciones basadas en el ADN.
Y podría tener un núcleo de taxones o un listado taxonómico, como ya he mencionado, donde tiene la distribución de las especies cubiertas.

Diapositiva 11 - ¿Faltan campos?
Tenemos muchos campos disponibles en GBIF por los que puede filtrar y limitar su búsqueda. Pero en algunos casos, es posible que no encuentre los campos que necesita para su análisis.
Si alguna vez necesitara un campo de este tipo, la forma correcta de conseguirlo, bueno, al menos de iniciar la discusión sobre cómo incorporar ese campo a GBIF, sería pasar por TDWG y el estándar Darwin Core.
Se pueden proponer nuevos términos y cambios para Darwin Core, pero hay que tener en cuenta que cambiar las normas sobre datos es un proceso impulsado por la comunidad que requiere mucho compromiso y paciencia, porque hay que debatirlo con los compañeros y encontrar un terreno común para añadir esos datos. Así que hay que considerar si el término ya existe pero requeriría una actualización, dónde sería mejor colocar el nuevo término. ¿Es específico de un taxón? ¿Es específico de un registro biológico o de un evento? ¿Tiene que ver con la ubicación?
Y también hay que pensar si el término es más adecuado en una extensión o en una de las tablas principales.
Puede que mucha gente no esté al tanto de las extensiones de estas tablas principales, pero hay muchas extensiones ahí fuera para servir a la comunidad que quiere compartir o utilizar datos.
Así que familiarícese con ellos antes de proponer o cambiar términos.

Diapositiva 12 - Metadatos del conjunto de datos
Una última cosa que tengo que mencionar sobre las normas de datos es que también hay una norma de datos llamada EML o Ecological Metadata Language (Lenguaje de Metadatos Ecológicos) que los publicadores utilizan para compartir información sobre el recurso del conjunto de datos en el que tienen todos sus datos. Es decir, por ejemplo, quiénes fueron las personas que participaron en el mantenimiento y la recopilación de los datos, el ámbito espacial y temporal general del conjunto de datos, el ámbito taxonómico del conjunto de datos y cualquier información específica sobre financiación y proyectos, así como los métodos y el diseño.
Así que esa es otro estándar, que no forma parte de la norma TDWG, a la que quizás también quieras echar un vistazo.
Tipos de conjuntos de datos
Más información en tipos de conjuntos de datos en el sitio web de GBIF.
También puede explorar cómo elegir un tipo de conjunto de datos .
Interpretación taxonómica
Para facilitar la búsqueda y la generación de métricas, todos los registros biológicos se corresponden con dos taxonomías:
Catalogue of Life eXtended Release (COL XR) - Esta es la taxonomía primaria utilizada por GBIF.
GBIF backbone - Esta es una taxonomía que, hasta hace poco, GBIF ha estado construyendo e integrando periódicamente. Se basa principalmente en una versión antigua del Catálogo de la Vida con taxones adicionales añadidos de forma automatizada desde otros conjuntos de datos taxonómicos. El proceso de construcción se ha interrumpido en favor de la versión ampliada del Catálogo de la Vida. El Backbone de GBIF ya no se actualizará, pero permanecerá disponible para compatibilidad con versiones anteriores. Todos los identificadores de GBIF Backbone serán preservados y soportados en la API.
| Soporte API para la interpretación de taxonomías junto con Índices taxonómicos están documentados en la documentación técnica de GBIF. |
¿Por qué GBIF necesita interpretación taxonómica?*
Sin ella, no podríamos hacer ninguna búsqueda taxonómica y sería difícil generar estadísticas y mapas coherentes.
Como se puede imaginar, no todos utilizan los mismos nombres o clasificación taxonómica. Esto genera variaciones considerables en los nombres de los niveles taxonómicos más altos y un gran número de sinónimos. El árbol taxonómico busca reunir todos estos nombres y organizarlos.
¿Cómo se generan las taxonomías?
Catalogue of Life es un índice global de especies cuyo objetivo es ofrecer una lista exhaustiva y autorizada de las especies del mundo. Se elabora a partir de múltiples conjuntos de datos taxonómicos y se actualiza periódicamente. La versión eXtended Release (COL XR) se basa en la versión base mediante la integración programática de fuentes de datos adicionales. Integra información de más de 58.000 fuentes de datos taxonómicos y nomenclaturales globales, regionales, nacionales y de gestión (listados taxonómicos) que se solapan, así como la procedente de la literatura digitalizada disponible en la infraestructura de Catalogue of Life ChecklistBank.
| Tenga en cuenta que muchos registros biológicos basados en secuencias no tienen nombres en latín pero son nombradas usando hipótesis de especies (UNITE: hongos) o códigos de barras (iBOL: principalmente animales). Ésa es la razón por la que la adición de estas dos fuentes principales de OTUs estables a la última versión del árbol taxonómico mejora significativamente la funcionalidad de indexación de GBIF para los datos sobre biodiversidad derivados de secuencias. |
¿Cómo se define el estatus taxonómico?

-
Aceptado: Un nombre taxonómicamente aceptado y actual
-
Provisionalmente aceptado: Tratado como aceptado, pero se duda de que sea correcto.
-
Sinónimo: Nombres que apuntan inequívocamente a una especie (sin especificar si es homo o heterotípica). Los sinónimos, en el sentido de CoL, incluyen también las variantes ortográficas y los errores ortográficos publicados.
-
Sinónimo ambiguo: Nombres que son ambiguos porque apuntan a la especie actual y a otra u otras, por ejemplo, homónimos, sinónimos pro-parte (en otras palabras, nombres que aparecen más de una vez en el Catálogo).
-
Aplicado incorrectamente: Un nombre mal aplicado. Generalmente va acompañado de un "según" (accordingTo) en el sinónimo para indicar la fuente donde se puede encontrar la aplicación incorrecta.
-
Nombre desnudo: Un nombre solo, sin ningún uso, ni sinónimo ni taxón.
GRSciColl
El Registro Mundial de Colecciones Científicas, o GRSciColl, es un centro de intercambio de información exhaustivo y elaborado por la comunidad sobre las colecciones científicas del registro de GBIF. Al proporcionar información sobre colecciones científicas físicas -su contenido, ubicación, contactos, instituciones asociadas y códigos e identificadores de colecciones- GRSciColl ofrece un recurso para una amplia gama de usos por parte de expertos, investigadores y miembros de la sociedad en general.
|
En este vídeo (02:11), Marie Grosjean, Administradora de Datos de GBIF, ofrece una introducción a GRSciColl. Si no puede ver el vídeo incrustado de Vimeo, puede descargarlo localmente (MP4 - 13,3 MB). |
Principios de datos mediados por GBIF
| En esta sección, conocerá los principios que GBIF sigue con respecto a los datos y cómo los datos del portal de GBIF son FAIR. |
Identificadores de objetos digitales
Un identificador de objeto digital, o DOI (Digital Object Identifier), es un identificador permanente standard que proporciona un enlace procesable, interoperable y persistente a cualquier entidad. El concepto es que el DOI difiere de las referencias de uso común, como los enlaces web URL, porque identifica un objeto en sí como una entidad de primera clase, no simplemente el lugar donde el objeto se encuentra actualmente.
En el contexto de GBIF.org, los DOI sirven como identificadores estables para cuatro tipos diferentes de cosas:
-
conjuntos de datos de la red GBIF
-
descargas de datos desde GBIF.org
-
artículos de investigación e informes publicados por revistas científicas, agencias y ONG
-
materiales depositados en un repositorio de uso general
GBIF asigna DOIs a todos los conjuntos de datos y descargas de registros biológicos. Cuando se utilizan datos siguiendo las practicas de citación del DOI se asegura una forma fácil y consistente de dar crédito a los titulares de los conjuntos de datos al mismo tiempo que permite la reproducibilidad. Los DOIs siempre resolverán las páginas del conjunto de datos o de descarga, incluso si los datos subyacentes ya no están disponibles.
GBIF comenzó a emitir DOIs el 3 de febrero de 2015. Las descargas solicitadas antes de esta fecha no tienen DOI, sin embargo, si desea citar descargas más antiguas, puede ponerse en contacto con helpdesk@gbif.org y le asignaremos DOI según corresponda.
Normas
Los datos disponibles a través de GBIF.org y sus servicios asociados son el resultado de la aplicación por parte de la red de Participantes y editores de GBIF de normas y convenciones compartidas para describir, registrar y estructurar miles de conjuntos de datos diferentes procedentes de cientos de instituciones de todo el mundo. Los estándares comunes son el principal habilitador para reunir los cientos de millones de registros primarios de biodiversidad en el índice de GBIF.
Dentro del dominio de la biodiversidad, el grupo más a menudo responsable del desarrollo y mantenimiento de estándares de datos es Biodiversity Information Standards. Esta asociación científica y educativa sin fines de lucro se centra en el desarrollo de normas para el intercambio de datos biológicos y de biodiversidad. Los miembros de la comunidad de biodiversidad generalmente se refieren a este grupo como TDWG —un recordatorio vestigio de su anterior manifestación como Grupo de Trabajo de bases de datos taxonómicas.
Los estándares usados comúnmente incluyen:
-
Darwin Core: El Estándar Darwin Core (DwC) ofrece un marco estable, sencillo y flexible para compilar datos de biodiversidad de fuentes variadas y variables. La mayoría de los conjuntos de datos compartidos a través de GBIF.org se publican utilizando el formato de Archivo Darwin Core (DwC-A).
-
Lenguaje de Metadatos Ecológicos (LME): Ecological Metadata Language es un estándar que registra información sobre conjuntos de datos ecológicos en una serie de tipos de documento XML modular y extensible. Las descripciones de conjuntos de datos en GBIF.org confian en 'metadatos'- es decir, la información sobre los datos- utilizando el estándard open-source EML, lo cual es administrado y mantenido por The Knowledge Network for Biocomplexity. Cada archivo de Darwin Core incluye como uno de su componentes un archivo EML (escrito en formato XML).
-
BioCASe/ABCD: The Biological Collection Access Service, comúnmente conocido como BioCASE, es una red internacional que enlaza datos de colecciones biológicas desde museos de historia natural, jardines botánicos/ zoológicos e instituciones de investigación. BioCASe protocol confía en Access to Biological Collections Data estándar de intercambio de daos, el cual administra también TDWG.
Datos abiertos
De acuerdo con una decision by the GBIF governing board^ de 2014, los publicadores de datos deben asignar una de las tres opciones Creative Commons a cada conjunto de datos de registros. La junta de gobierno reconoció la necesidad de una mayor claridad tanto para los publicadores de datos como los usuarios sobre cómo se pueden utilizar los datos cuando se comparten vía GBIF.org. https://creativecommons.org/[Creative Commons es una organización sin fines de lucro que ayuda a superar los obstáculos legales para compartir el conocimiento y la creatividad a fin de abordar los desafíos apremiantes del mundo.
| Tenga en cuenta que la licencia CC-BY-NC tiene un efecto significativo en la reutilización de los datos. GBIF anima a los publicadores de datos a elegir la opción más abierta posible. Es importante señalar que las imágenes no están sujetas a la misma licencia que se aplica al conjunto de datos y pueden tener términos de uso más restringidos. Por último, la atribución/citación es una norma de comunidad, así que incluso si los publicadores han renunciado a las condiciones de uso, se espera que tengan atribución. |
Datos FAIR
Numerosos artículos de 2011 a 2016 documentaron una crisis de la reproducibilidad científica (véase más abajo). En 2016, se publicaron los FAIR Guiding Principles for scientific data management and stewardship en Scientific Data. Los principios fueron diseñados para mejorar la encontrabilidad, accesibilidad, interoperabilidad y reutilización de los conjuntos de datos y abordar «una necesidad urgente de mejorar la infraestructura de apoyo a la reutilización de los datos académicos.» La aplicación de estos principios comenzó en 2018. Puede obtener más información sobre How to GO FAIR en GO-FAIR.org.


Los datos que se encuentran en GBIF.org son FAIR.
Referencias bibliográficas
Baker (2016), 1,500 científicos se pronuncian sobre la reproducibilidad. Natura 533: 452-454 (26 de mayo 2016) doi: 10. 1038/533452a
Baker (2016) Reproducibility: Seek out stronger science. Nature 537: 703-704 (29 September 2016) doi:10.1038/nj7622-703a
Nature editorial (2016) Reality check on reproducibility. Nature 533: 437 (26 May 2016) doi:10.1038/533437a
Baker (2016) Statisticians issue warning over misuse of P values. Nature 531: 151 (10 March 2016) doi:10.1038/nature.2016.19503
Nosek et al. (2015) Promoting an open research culture. Science 348(6242): 1422-1425. DOI:10.1126/science.aab2374
Leek and Peng (2015) Statistics: P values are just the tip of the iceberg. Nature 520: 612 (30 April 2015) doi:10.1038/520612°
Nuzzo (2015) How scientists fool themselves – and how they can stop. Nature 526: 182–185 (08 October 2015) doi:10.1038/526182a
Hayden (2013) Weak statistical standards implicated in scientific irreproducibility. Nature doi:10.1038/nature.2013.14131
Young (2012) Replication studies: Bad copy. Nature 485, 298–300 (17 May 2012) doi:10.1038/485298a
Callaway (2011) Reports finds massive fraud at Dutch universities. Nature 479, 15 (1 November 2011) doi:10.1038/479015a
Métricas de datos
| En esta sección se revisan las distintas métricas disponibles para los conjuntos de datos. |
Uno de los muchos beneficios de publicar datos a través de GBIF es que, durante el proceso de indexación, GBIF analiza todos los conjuntos de datos y produce métricas acerca de ellos. Estas métricas están disponibles de varias maneras diferentes:
-
tendencias globales
-
páginas de país
-
estadísticas sobre el contenido del conjunto de datos
-
actividad de descarga del conjunto de datos
Los participantes y los publicadores pueden usar esta información para mejorar la calidad de sus conjuntos de datos, por ejemplo, solucionando problemas detectados durante el proceso de indexación. También pueden usar las estadísticas de acceso como evidencia del interés real de los usuarios en sus conjuntos de datos y del uso potencial de los datos publicados.
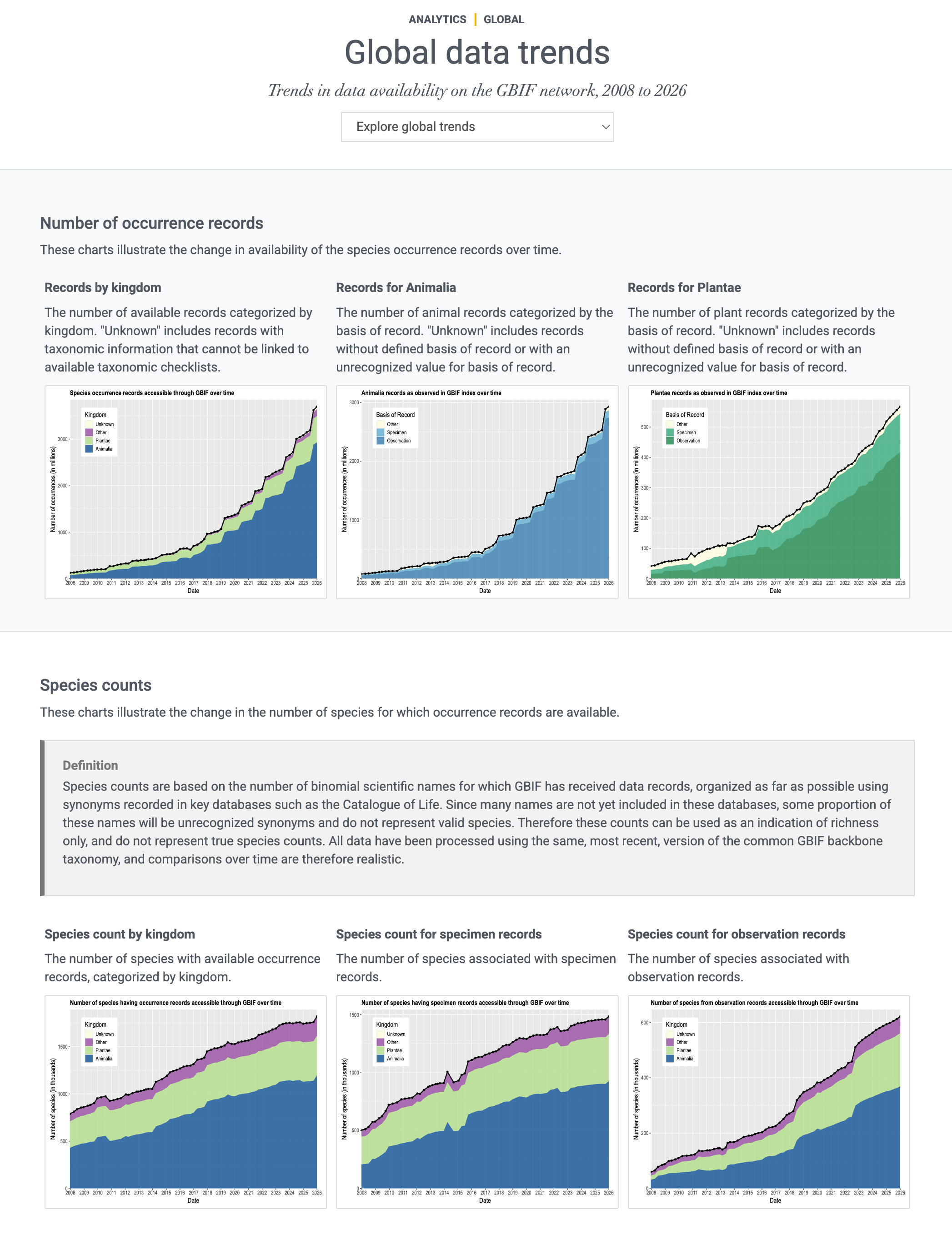
Tendencias globales de datos
GBIF.org actualiza regularmente los análisis para proporcionar una visión general de las tendencias globales en los datos desde 2008 hasta el presente. Los gráficos ilustran tendencias en:
-
registros biológicos
-
número de especies
-
tiempo y estacionalidad
-
completitud y precisión
-
cobertura geográfica para especies registradas
-
intercambio de datos con el país de origen
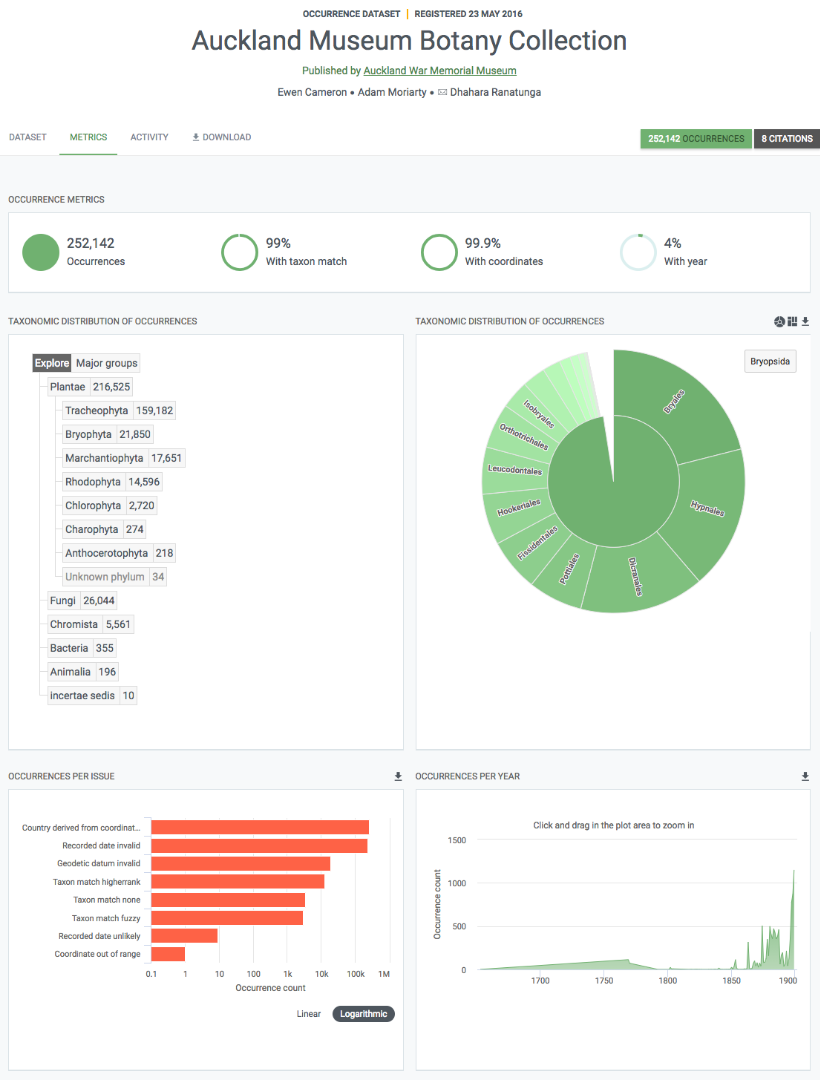
Estadísticas sobre el contenido de los conjuntos de datos
Cada página de un conjunto de datos incluye una pestaña llamada "Estadísticas". Esta pestaña da acceso a gráficos y tablas resultantes del análisis del contenido del conjunto de datos. Esto incluye resúmenes de:
-
Distribución taxonómica (lista y gráfico)
-
Registros biológicos por incidencia
-
Registros biológicos por año
Las tablas y gráficos son interactivos, usted puede hacer clic para filtrar y explorar. Además, las gráficas se pueden descargar con fines informativos.
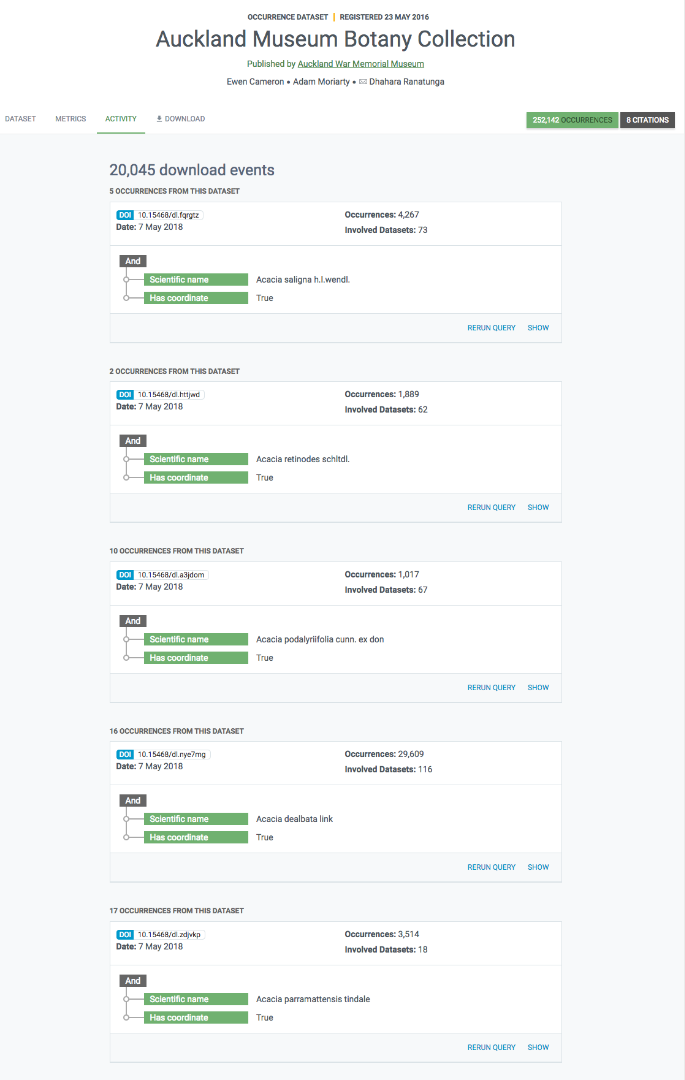
Registro del acceso a los datos
Hay una tercera pestaña en la página de los conjuntos de datos de registros biológicos etiquetada como 'Actividad'. En esta pestaña puede ver una lista de todas las solicitudes de descarga que incluyen registros de ese conjunto de datos, incluyendo el DOI de la descarga para un seguimiento fácil.
Revisión
|
Pon a prueba tus conocimientos sobre los conceptos tratados en este módulo. Algunas preguntas pueden tener varias respuestas correctas. Puede leer más sobre las respuestas en el Apéndice de Soluciones. |